各位游戏大佬大家好,今天小编为大家分享关于gg修改器root框架_gg修改器框架免root版中文的内容,轻松修改游戏数据,赶快来一起来看看吧。
整个架构是基于 Iceberg 构建数据仓库分层,经过 Kafka 处理数据都实时存储在对应的 Iceberg 分层中,实时数据结果经过最后分析存储在 Clickhouse 中,离线数据分析结果直接从 Iceberg-DWS 层中获取数据分析,分析结果存入 MySQL 中,Iceberg 其它层供临时性业务分析,最终 Clickhouse 和 MySQL 中的结果通过可视化工具展示出来。

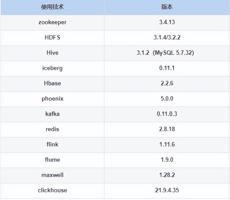
下表列出项目中使用的大数据技术组件及各个组件的版本,如下:
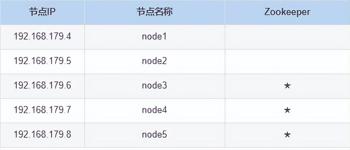
这里我们使用 5 台节点来安装各个大数据组件,每台节点给了 3G 内存,4 个 core,并且每台节点已经关闭防火墙、配置主机名、设置 yum 源、各个节点时间同步、各个节点两两免密、安装 JDK 操作。5 台节点信息如下:
这里搭建 zookeeper 版本为 3.4.13,搭建 zookeeper 对应的角色分布如下:
具体搭建步骤如下:
在 node1,node2,node3,node4,node5 各个节点都创建/software 目录,方便后期安装技术组件使用。
mkdir /software
将 zookeeper 安装包上传到 node3 节点/software 目录下并解压:
[root@node3 software]# tar -zxvf ./zookeeper-3.4.13.tar.gz
在 node3 节点配置环境变量:
#进入vim /etc/profile,在最后加入:export ZOOKEEPER_HOME=/software/zookeeperexport PATH=$PATH:$ZOOKEEPER_HOME/bin
#使配置生效source /etc/profile
进入“/software/zookeeper-3.4.13/conf”修改 zoo_sample.cfg 为 zoo.cfg
[root@node3 conf]# mv zoo_sample.cfg zoo.cfg
配置 zoo.cfg 中内容如下:
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/opt/data/zookeeper
clientPort=2181
server.1=node3:2888:3888
server.2=node4:2888:3888
server.3=node5:2888:3888
[root@node3 software]# scp -r ./zookeeper-3.4.13 node4:/software/[root@node3 software]# scp -r ./zookeeper-3.4.13 node5:/software/
在 node3,node4,node5 各个节点上创建 zoo.cfg 中指定的数据目录“/opt/data/zookeeper”。
mkdir -p /opt/data/zookeeper
在 node4,node5 节点配置 zookeeper 环境变量
#进入vim /etc/profile,在最后加入:export ZOOKEEPER_HOME=/software/zookeeperexport PATH=$PATH:$ZOOKEEPER_HOME/bin
#使配置生效source /etc/profile
在 node3,node4,node5 各个节点路径“/opt/data/zookeeper”中添加 myid 文件分别写入 1,2,3:
#在 node3 的/opt/data/zookeeper 中创建 myid 文件写入 1
#在 node4 的/opt/data/zookeeper 中创建 myid 文件写入 2
#在 node5 的/opt/data/zookeeper 中创建 myid 文件写入 3
#各个节点启动zookeeper命令zkServer.sh start
#检查各个节点zookeeper进程状态zkServer.sh status
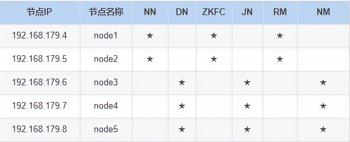
这里搭建 HDFS 版本为 3.1.4,搭建 HDFS 对应的角色在各个节点分布如下:
搭建具体步骤如下:
yum -y install psmisc
[root@node1 software]# tar -zxvf ./hadoop-3.1.4.tar.gz
[root@node1 software]# vim /etc/profileexport HADOOP_HOME=/software/hadoop-3.1.4/export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:
#使配置生效source /etc/profile
#导入 JAVA_HOME
export JAVA_HOME=/usr/java/jdk1.8.0_181-amd64/
<configuration> <property> <!--这里配置逻辑名称,可以随意写 --> <name>dfs.nameservices</name> <value>mycluster</value> </property> <property> <!-- 禁用权限 --> <name>dfs.permissions.enabled</name> <value>false</value> </property> <property> <!-- 配置namenode 的名称,多个用逗号分割 --> <name>dfs.ha.namenodes.mycluster</name> <value>nn1,nn2</value> </property> <property> <!-- dfs.namenode.rpc-address.[nameservice ID].[name node ID] namenode 所在服务器名称和RPC监听端口号 --> <name>dfs.namenode.rpc-address.mycluster.nn1</name> <value>node1:8020</value> </property> <property> <!-- dfs.namenode.rpc-address.[nameservice ID].[name node ID] namenode 所在服务器名称和RPC监听端口号 --> <name>dfs.namenode.rpc-address.mycluster.nn2</name> <value>node2:8020</value> </property> <property> <!-- dfs.namenode.http-address.[nameservice ID].[name node ID] namenode 监听的HTTP协议端口 --> <name>dfs.namenode.http-address.mycluster.nn1</name> <value>node1:50070</value> </property> <property> <!-- dfs.namenode.http-address.[nameservice ID].[name node ID] namenode 监听的HTTP协议端口 --> <name>dfs.namenode.http-address.mycluster.nn2</name> <value>node2:50070</value> </property>
<property> <!-- namenode 共享的编辑目录, journalnode 所在服务器名称和监听的端口 --> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://node3:8485;node4:8485;node5:8485/mycluster</value> </property>
<property> <!-- namenode高可用代理类 --> <name>dfs.client.failover.proxy.provider.mycluster</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property>
<property> <!-- 使用ssh 免密码自动登录 --> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> </property>
<property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/root/.ssh/id_rsa</value> </property>
<property> <!-- journalnode 存储数据的地方 --> <name>dfs.journalnode.edits.dir</name> <value>/opt/data/journal/node/local/data</value> </property>
<property> <!-- 配置namenode自动切换 --> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property>
</configuration>
<configuration> <property> <!-- 为Hadoop 客户端配置默认的高可用路径 --> <name>fs.defaultFS</name> <value>hdfs://mycluster</value> </property> <property> <!-- Hadoop 数据存放的路径,namenode,datanode 数据存放路径都依赖本路径,不要使用 file:/ 开头,使用绝对路径即可 namenode 默认存放路径 :file://${hadoop.tmp.dir}/dfs/name datanode 默认存放路径 :file://${hadoop.tmp.dir}/dfs/data --> <name>hadoop.tmp.dir</name> <value>/opt/data/hadoop/</value> </property>
<property> <!-- 指定zookeeper所在的节点 --> <name>ha.zookeeper.quorum</name> <value>node3:2181,node4:2181,node5:2181</value> </property>
</configuration>
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.env-whitelist</name> <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value> </property>
<property> <!-- 配置yarn为高可用 --> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> </property> <property> <!-- 集群的唯一标识 --> <name>yarn.resourcemanager.cluster-id</name> <value>mycluster</value> </property> <property> <!-- ResourceManager ID --> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm1,rm2</value> </property> <property> <!-- 指定ResourceManager 所在的节点 --> <name>yarn.resourcemanager.hostname.rm1</name> <value>node1</value> </property> <property> <!-- 指定ResourceManager 所在的节点 --> <name>yarn.resourcemanager.hostname.rm2</name> <value>node2</value> </property> <property> <!-- 指定ResourceManager Http监听的节点 --> <name>yarn.resourcemanager.webapp.address.rm1</name> <value>node1:8088</value> </property> <property> <!-- 指定ResourceManager Http监听的节点 --> <name>yarn.resourcemanager.webapp.address.rm2</name> <value>node2:8088</value> </property> <property> <!-- 指定zookeeper所在的节点 --> <name>yarn.resourcemanager.zk-address</name> <value>node3:2181,node4:2181,node5:2181</value></property><property> <!-- 关闭虚拟内存检查 --> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value></property> <!-- 启用节点的内容和CPU自动检测,最小内存为1G --> <!--<property> <name>yarn.nodemanager.resource.detect-hardware-capabilities</name> <value>true</value> </property>--></configuration>
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property></configuration>
[root@node1 ~]# vim /software/hadoop-3.1.4/etc/hadoop/workersnode3node4node5
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_JOURNALNODE_USER=root
HDFS_ZKFC_USER=root
YARN_RESOURCEMANAGER_USER=root
YARN_NODEMANAGER_USER=root
[root@node1 ~]# scp -r /software/hadoop-3.1.4 node2:/software/[root@node1 ~]# scp -r /software/hadoop-3.1.4 node3:/software/[root@node1 ~]# scp -r /software/hadoop-3.1.4 node4:/software/[root@node1 ~]# scp -r /software/hadoop-3.1.4 node5:/software/
#分别在node2、node3、node4、node5节点上配置HADOOP_HOMEvim /etc/profileexport HADOOP_HOME=/software/hadoop-3.1.4/export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:
#最后记得Sourcesource /etc/profile
#在node3,node4,node5节点上启动zookeeperzkServer.sh start
#在node1上格式化zookeeper[root@node1 ~]# hdfs zkfc -formatZK
#在每台journalnode中启动所有的journalnode,这里就是node3,node4,node5节点上启动hdfs --daemon start journalnode
#在node1中格式化namenode[root@node1 ~]# hdfs namenode -format
#在node1中启动namenode,以便同步其他namenode[root@node1 ~]# hdfs --daemon start namenode
#高可用模式配置namenode,使用下列命令来同步namenode(在需要同步的namenode中执行,这里就是在node2上执行):[root@node2 software]# hdfs namenode -bootstrapStandby
#node1上启动HDFS,启动Yarn[root@node1 sbin]# start-dfs.sh[root@node1 sbin]# start-yarn.sh
注意以上也可以使用 start-all.sh 命令启动 Hadoop 集群。
访问 HDFS : http://node1:50070
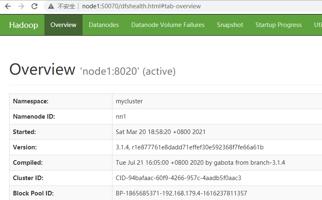
访问 Yarn WebUI :http://node1:8088
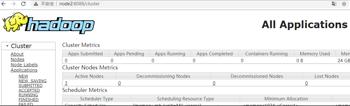
#停止集群
[root@node1 ~]# stop-dfs.sh
[root@node1 ~]# stop-yarn.sh
注意:以上也可以使用 stop-all.sh 停止集群。
这里搭建 Hive 的版本为 3.1.2,搭建 Hive 的节点划分如下:
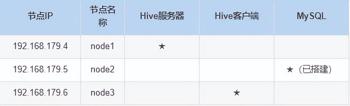
搭建具体步骤如下:
[root@node1 ~]# cd /software/[root@node1 software]# tar -zxvf ./apache-hive-3.1.2-bin.tar.gz[root@node1 software]# mv apache-hive-3.1.2-bin hive-3.1.2
[root@node1 ~]# scp -r /software/hive-3.1.2/ node3:/software/
vim /etc/profileexport HIVE_HOME=/software/hive-3.1.2/export PATH=$PATH:$HIVE_HOME/bin
#source 生效source /etc/profile
<configuration> <property> <name>hive.metastore.warehouse.dir</name> <value>/user/hive/warehouse</value> </property> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://node2:3306/hive?createDatabaseIfNotExist=true&useSSL=false</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value&.mysql.jdbc.Driver</value> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>123456</value> </property></configuration>
<configuration> <property> <name>hive.metastore.warehouse.dir</name> <value>/user/hive/warehouse</value> </property> <property> <name>hive.metastore.local</name> <value>false</value> </property> <property> <name>hive.metastore.uris</name> <value>thrift://node1:9083</value> </property></configuration>
#删除Hive lib目录下“guava-19.0.jar ”包[root@node1 ~]# rm -rf /software/hive-3.1.2/lib/guava-19.0.jar [root@node3 ~]# rm -rf /software/hive-3.1.2/lib/guava-19.0.jar
#将Hadoop lib下的“guava”包拷贝到Hive lib目录下[root@node1 ~]# cp /software/hadoop-3.1.4/share/mon/lib/guava-27.0-jre.jar /software/hive-3.1.2/lib/
[root@node3 ~]# cp /software/hadoop-3.1.4/share/mon/lib/guava-27.0-jre.jar /software/hive-3.1.2/lib/
上传后,需要将 mysql 驱动包传入 $HIVE_HOME/lib/目录下,这里 node1,node3 节点都需要传入。
#初始化hive,hive2.x版本后都需要初始化[root@node1 ~]# schematool -dbType mysql -initSchema
#在node1中登录Hive ,创建表test[root@node1 conf]# hivehive> create table test (id int,name string,age int ) row format delimited fields terminated by ’ ’;
#向表test中插入数据hive> insert into test values(1,"zs",18);
#在node1启动Hive metastore[root@node1 hadoop]# hive --service metastore &
#在node3上登录Hive客户端查看表数据[root@node3 lib]# hivehive> select * from test;OK1 zs 18
Iceberg 就是一种表格式,支持使用 Hive 对 Iceberg 进行读写操作,但是对 Hive 的版本有要求,如下:
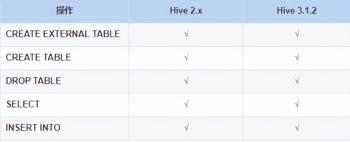
这里基于 Hive3.1.2 版本进行 Hive 集成 Iceberg。
想要使用 Hive 支持查询 Iceberg 表,首先需要下载“iceberg-hive-runtime.jar”,Hive 通过该 Jar 可以加载 Hive 或者更新 Iceberg 表元数据信息。下载地址:https://iceberg.apache.org/#releases/
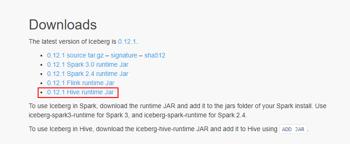
将以上 jar 包下载后,上传到 Hive 服务端和客户端对应的 $HIVE_HOME/lib 目录下。另外在向 Hive 中 Iceberg 格式表插入数据时需要到“libfb303-0.9.3.jar”包,将此包也上传到 Hive 服务端和客户端对应的 $HIVE_HOME/lib 目录下。
在 Hive 客户端 $HIVE_HOME/conf/hive-site.xml 中追加如下配置:
<property> <name>iceberg.engine.hive.enabled</name> <value>true</value></property>
从 Hive 引擎的角度来看,在运行环境中有 Catalog 概念(catalog 主要描述了数据集的位置信息,就是元数据),Hive 与 Iceberg 整合时,Iceberg 支持多种不同的 Catalog 类型,例如:Hive、Hadoop、第三方厂商的 AWS Glue 和自定义 Catalog。在实际应用场景中,Hive 可能使用上述任意 Catalog,甚至跨不同 Catalog 类型 join 数据,为此 Hive 提供了 org.apache.iceberg.mr.hive.HiveIcebergStorageHandler(位于包 iceberg-hive-runtime.jar)来支持读写 Iceberg 表,并通过在 Hive 中设置“iceberg.catalog..type”属性来决定加载 Iceberg 表的方式,该属性可以配置:hive、hadoop,其中“”是自己随便定义的名称,主要是在 hive 中创建 Iceberg 格式表时配置 iceberg.catalog 属性使用。
在 Hive 中创建 Iceberg 格式表时,根据创建 Iceberg 格式表时是否指定 iceberg.catalog 属性值,有以下三种方式决定 Iceberg 格式表如何加载(数据存储在什么位置)。
这种方式就是说如果在 Hive 中创建 Iceberg 格式表时,不指定 iceberg.catalog 属性,那么数据存储在对应的 hive warehouse 路径下。
在 Hive 客户端 node3 节点进入 Hive,操作如下:
在 Hive 中创建 iceberg 格式表
create table test_iceberg_tbl1(id int ,name string,age int) partitioned by (dt string) stored by ’org.apache.iceberg.mr.hive.HiveIcebergStorageHandler’;
在 Hive 中加载如下两个包,在向 Hive 中插入数据时执行 MR 程序时需要使用到
hive> add jar /software/hive-3.1.2/lib/iceberg-hive-runtime-0.12.1.jar;hive> add jar /software/hive-3.1.2/lib/libfb303-0.9.3.jar;
向表中插入数据
hive> insert into test_iceberg_tbl1 values (1,"zs",18,"20211212");
查询表中的数据
hive> select * from test_iceberg_tbl1;OK1 zs 18 20211212
在 Hive 默认的 warehouse 目录下可以看到创建的表目录:
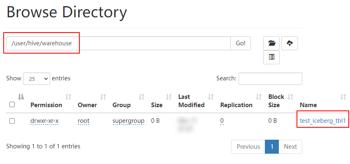
这种情况就是说在 Hive 中创建 Iceberg 格式表时,如果指定了 iceberg.catalog 属性值,那么数据存储在指定的 catalog 名称对应配置的目录下。
在 Hive 客户端 node3 节点进入 Hive,操作如下:
注册一个 HiveCatalog 叫 another_hive
hive> set iceberg.catalog.another_hive.type=hive;
在 Hive 中创建 iceberg 格式表
create table test_iceberg_tbl2(id int,name string,age int)partitioned by (dt string)stored by ’org.apache.iceberg.mr.hive.HiveIcebergStorageHandler’tblproperties (’iceberg.catalog’=’another_hive’);
在 Hive 中加载如下两个包,在向 Hive 中插入数据时执行 MR 程序时需要使用到
hive> add jar /software/hive-3.1.2/lib/iceberg-hive-runtime-0.12.1.jar;hive> add jar /software/hive-3.1.2/lib/libfb303-0.9.3.jar;
插入数据,并查询
hive> insert into test_iceberg_tbl2 values (2,"ls",20,"20211212");hive> select * from test_iceberg_tbl2;OK2 ls 20 20211212
以上方式指定“iceberg.catalog.another_hive.type=hive”后,实际上就是使用的 hive 的 catalog,这种方式与第一种方式不设置效果一样,创建后的表存储在 hive 默认的 warehouse 目录下。也可以在建表时指定 location 写上路径,将数据存储在自定义对应路径上。
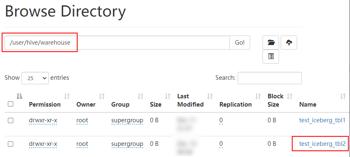
除了可以将 catalog 类型指定成 hive 之外,还可以指定成 hadoop,在 Hive 中创建对应的 iceberg 格式表时需要指定 location 来指定 iceberg 数据存储的具体位置,这个位置是具有一定格式规范的自定义路径。在 Hive 客户端 node3 节点进入 Hive,操作如下:
注册一个 HadoopCatalog 叫 hadoop
hive> set iceberg.catalog.hadoop.type=hadoop;
使用 HadoopCatalog 时,必须设置“iceberg.catalog..warehouse”指定 warehouse 路径
hive> set iceberg.catalog.hadoop.warehouse=hdfs://mycluster/iceberg_data;
在 Hive 中创建 iceberg 格式表,这里创建成外表
create external table test_iceberg_tbl3(id int,name string,age int)partitioned by (dt string)stored by ’org.apache.iceberg.mr.hive.HiveIcebergStorageHandler’location ’hdfs://mycluster/iceberg_data/default/test_iceberg_tbl3’tblproperties (’iceberg.catalog’=’hadoop’);
注意:以上 location 指定的路径必须是“iceberg.catalog.hadoop.warehouse”指定路径的子路径,格式必须是 ${iceberg.catalog.hadoop.warehouse}/${当前建表使用的 hive 库}/${创建的当前 iceberg 表名}
在 Hive 中加载如下两个包,在向 Hive 中插入数据时执行 MR 程序时需要使用到
hive> add jar /software/hive-3.1.2/lib/iceberg-hive-runtime-0.12.1.jar;hive> add jar /software/hive-3.1.2/lib/libfb303-0.9.3.jar;
插入数据,并查询
hive> insert into test_iceberg_tbl3 values (3,"ww",20,"20211213");hive> select * from test_iceberg_tbl3;OK3 ww 20 20211213
在指定的“iceberg.catalog.hadoop.warehouse”路径下可以看到创建的表目录:
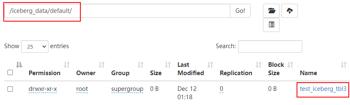
这种情况就是说如果 HDFS 中已经存在 iceberg 格式表,我们可以通过在 Hive 中创建 Icerberg 格式表指定对应的 location 路径映射数据。
在 Hive 客户端中操作如下:
CREATE TABLE test_iceberg_tbl4 ( id int, name string, age int, dt string)STORED BY ’org.apache.iceberg.mr.hive.HiveIcebergStorageHandler’ LOCATION ’hdfs://mycluster/spark/person’ TBLPROPERTIES (’iceberg.catalog’=’location_based_table’);
注意:指定的 location 路径下必须是 iceberg 格式表数据,并且需要有元数据目录才可以。不能将其他数据映射到 Hive iceberg 格式表。
由于 Hive 建表语句分区语法“Partitioned by”的限制,如果使用 Hive 创建 Iceberg 格式表,目前只能按照 Hive 语法来写,底层转换成 Iceberg 标识分区,这种情况下不能使用 Iceberge 的分区转换,例如:days(timestamp),如果想要使用 Iceberg 格式表的分区转换标识分区,需要使用 Spark 或者 Flink 引擎创建表。
这里选择 HBase 版本为 2.2.6,搭建 HBase 各个角色分布如下:
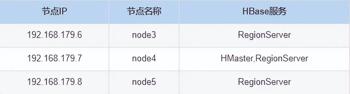
具体搭建步骤如下:
#将下载好的HBase安装包上传至node4节点/software下,并解压[root@node4 software]# tar -zxvf ./hbase-2.2.6-bin.tar.gz
当前节点配置 HBase 环境变量
#配置HBase环境变量[root@node4 software]# vim /etc/profileexport HBASE_HOME=/software/hbase-2.2.6/export PATH=$PATH:$HBASE_HOME/bin
#使环境变量生效[root@node4 software]# source /etc/profile
#配置 HBase JDK
export JAVA_HOME=/usr/java/jdk1.8.0_181-amd64/
#配置 HBase 不使用自带的 zookeeper
export HBASE_MANAGES_ZK=false
<configuration> <property> <name>hbase.rootdir</name> <value>hdfs://mycluster/hbase</value> </property> <property> <name>hbase.cluster.distributed</name> <value>true</value> </property> <property> <name>hbase.zookeeper.quorum</name> <value>node3,node4,node5</value> </property> <property> <name>hbase.unsafe.stream.capability.enforce</name> <value>false</value> </property></configuration>
node3
node4
node5
手动创建 $HBASE_HOME/conf/backup-masters 文件,指定备用的 HMaster,需要手动创建文件,这里写入 node5,在 HBase 任意节点都可以启动 HMaster,都可以成为备用 Master ,可以使用命令:hbase-daemon.sh start master 启动。
#创建 $HBASE_HOME/conf/backup-masters 文件,写入node5[root@node4 conf]# vim backup-mastersnode5
[root@node4 conf]# scp /software/hadoop-3.1.4/etc/hadoop/hdfs-site.xml /software/hbase-2.2.6/conf/
[root@node4 software]# cd /software[root@node4 software]# scp -r ./hbase-2.2.6 node3:/software/[root@node4 software]# scp -r ./hbase-2.2.6 node5:/software/
# 注意:在node3、node5上配置HBase环境变量。vim /etc/profileexport HBASE_HOME=/software/hbase-2.2.6/export PATH=$PATH:$HBASE_HOME/bin
#使环境变量生效source /etc/profile
#注意:一定要重启Zookeeper,重启HDFS,在node4节点上启动HBase集群[root@node4 software]# start-hbase.sh
访问 WebUI,http://node4:16010。停止集群:在任意一台节点上 stop-hbase.sh
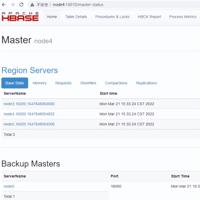
在 Hbase 中创建表 test,指定’cf1’,’cf2’两个列族,并向表 test 中插入几条数据:
#进入hbase[root@node4 ~]# hbase shell
#创建表testcreate ’test’,’cf1’,’cf2’
#查看创建的表list
#向表test中插入数据put ’test’,’row1’,’cf1:id’,’1’put ’test’,’row1’,’cf1:name’,’zhangsan’put ’test’,’row1’,’cf1:age’,18
#查询表test中rowkey为row1的数据get ’test’,’row1’
这里搭建 Phoenix 版本为 5.0.0,Phoenix 采用单机安装方式即可,这里将 Phoenix 安装到 node4 节点上。

Phoenix 下载及安装步骤如下:
Phoenix 对应的 HBase 有版本之分,可以从官网:http://phoenix.apache.org/download.html来下载,要对应自己安装的 HBase 版本下载。我们这里安装的 HBase 版本为 2.2.6,这里下载 Phoenix5.0.0 版本。下载地址如下:
http://archive.apache.org/dist/phoenix/apache-phoenix-5.0.0-HBase-2.0/bin/

注意:不要下载 phoenix5.1.2 版本,与 Hbase2.2.6 不兼容
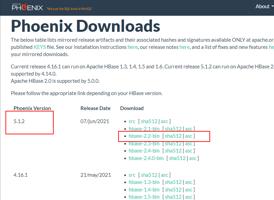
[root@node4 ~]# cd /software/[root@node4 software]# tar -zxvf ./apache-phoenix-5.0.0-HBase-2.0-bin.tar.gz
将前面解压好安装包下的 phoenix 开头的包发送到每个 HBase 节点下的 lib 目录下。
[root@node4 ~]# cd /software/apache-phoenix-5.0.0-HBase-2.0-bin
#直接复制到node4节点对应的HBase目录下[root@node4 apache-phoenix-5.0.0-HBase-2.0-bin]# cp ./phoenix-*.jar /software/hbase-2.2.6/lib/
#发送到node3,node5两台HBase节点[root@node4 apache-phoenix-5.0.0-HBase-2.0-bin]# scp ./phoenix-*.jar node3:/software/hbase-2.2.6/lib/
[root@node4 apache-phoenix-5.0.0-HBase-2.0-bin]# scp ./phoenix-*.jar node5:/software/hbase-2.2.6/lib/
将 HDFS 中的 core-site.xml、hdfs-site.xml、hbase-site.xml 复制到 Phoenix bin 目录下。
[root@node4 ~]# cp /software/hadoop-3.1.4/etc/hadoop/core-site.xml /software/apache-phoenix-5.0.0-HBase-2.0-bin/bin
[root@node4 ~]# cp /software/hadoop-3.1.4/etc/hadoop/hdfs-site.xml /software/apache-phoenix-5.0.0-HBase-2.0-bin/bin
#输入yes,覆盖Phoenix目录下的hbase-site.xml[root@node4 ~]# cp /software/hbase-2.2.6/conf/hbase-site.xml /software/apache-phoenix-5.0.0-HBase-2.0-bin/bin/
[root@node1 ~]# start-all.sh
[root@node4 ~]# start-hbase.sh (如果已经启动Hbase,一定要重启HBase)
#启动Phoenix[root@node4 ~]# cd /software/apache-phoenix-5.0.0-HBase-2.0-bin/bin/
#启动时可以不指定后面的zookeeper,默认连接当前节点的zookeeper,多个zookeeper节点逗号隔开,最后一个写端口2181
[root@node4 bin]# ./sqlline.py node3,node4,node5:2181
#退出Phoenix,使用!quit或者!exit0: jdbc:phoenix:node3,node4,node5:2181> !quitClosing: org.apache.phoenix.jdbc.PhoenixConnection
#查看Phoenix表0: jdbc:phoenix:node3,node4,node5:2181> !tables
#Phoenix中创建表 test,指定映射到HBase的列族为f10: jdbc:phoenix:node3,node4,node5:2181> create table test(id varchar primary key ,f1.name varchar,f1.age integer);
#向表 test中插入数据upsert into test values (’1’,’zs’,18);
#查询插入的数据0: jdbc:phoenix:node3,node4,node5:2181> select * from test;+-----+-------+------+| ID | NAME | AGE |+-----+-------+------+| 1 | zs | 18 |+-----+-------+------+
#在HBase中查看对应的数据,hbase中将非String类型的value数据全部转为了16进制hbase(main):013:0> scan ’TEST’

注意:在 Phoenix 中创建的表,插入数据时,在 HBase 中查看发现对应的数据都进行了 16 进制编码,这里默认 Phoenix 中对数据进行的编码,我们在 Phoenix 中建表时可以指定“column_encoded_bytes=0”参数,不让 Phoenix 对 column family 进行编码。例如以下建表语句,在 Phoenix 中插入数据后,在 HBase 中可以查看到正常格式数据:
create table mytable ("id" varchar primary key ,"cf1"."name" varchar,"cf1"."age" varchar) column_encoded_bytes=0;
upsert into mytable values (’1’,’zs’,’18’);
以上再次在 HBase 中查看,显示数据正常

这里选择 Kafka 版本为 0.11.0.3,对应的搭建节点如下:
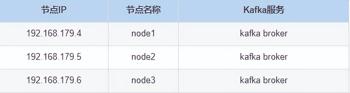
搭建详细步骤如下:
[root@node1 software]# tar -zxvf ./kafka_2.11-0.11.0.3.tgz
在 node3 节点上配置 Kafka,进入/software/kafka_2.11-0.11.0.3/config/中修改 server.properties,修改内容如下:
broker.id=0 #注意:这里要唯一的Integer类型port=9092 #kafka写入数据的端口log.dirs=/kafka-logs #真实数据存储的位置zookeeper.connect=node3:2181,node4:2181,node5:2181 #zookeeper集群
[root@node1 software]# scp -r /software/kafka_2.11-0.11.0.3 node2:/software/
[root@node1 software]# scp -r /software/kafka_2.11-0.11.0.3 node3:/software/
node2、node3 节点修改 $KAFKA_HOME/config/server.properties 文件中的 broker.id,node2 中修改为 1,node3 节点修改为 2。
在 node1,node2,node3 节点/software/kafka_2.11-0.11.0.3 路径中编写 Kafka 启动脚本“startKafka.sh”,内容如下:
nohup bin/kafka-server-start.sh config/server.properties > kafkalog.txt 2>&1 &
node1,node2,node3 节点配置完成后修改“startKafka.sh”脚本执行权限:
chmod +x ./startKafka.sh
在 node1,node2,node3 三台节点上分别执行/software/kafka/startKafka.sh 脚本,启动 Kafka:
[root@node1 kafka_2.11-0.11.0.3]# ./startKafka.sh [root@node2 kafka_2.11-0.11.0.3]# ./startKafka.sh [root@node3 kafka_2.11-0.11.0.3]# ./startKafka.sh
#创建topic ./kafka-topics.sh --zookeeper node3:2181,node4:2181,node5:2181 --create --topic testtopic --partitions 3 --replication-factor 3
#console控制台向topic 中生产数据./kafka-console-producer.sh --broker-list node1:9092,node2:9092,node3:9092 --topic testtopic
#console控制台消费topic中的数据./kafka-console-consumer.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --topic testtopic
这里选择 Redis 版本为 2.8.18 版本,Redis 安装在 node4 节点上,节点分布如下:

具体搭建步骤如下:
[root@node4 ~]# cd /software/[root@node4 software]# tar -zxvf ./redis-2.8.18.tar.gz
[root@node4 ~]# yum -y install gcc tcl
进入/software/redis-2.8.18 目录中,编译 redis。
#创建安装目录[root@node4 ~]# mkdir -p /software/redis
#进入redis编译目录,安装redis[root@node4 ~]# cd /software/redis-2.8.18[root@node4 redis-2.8.18]# make PREFIX=/software/redis install
注意:现在就可以使用 redis 了,进入/software/redis/bin 下,就可以执行 redis 命令。
#将redis-server链接到/usr/local/bin/目录下,后期加入系统服务时避免报错[root@node4 ~]# ln -sf /software/redis-2.8.18/src/redis-server /usr/local/bin/
#执行如下命令,配置redis Server,一直回车即可[root@node4 ~]# cd /software/redis-2.8.18/utils/[root@node4 utils]# ./install_server.sh
#执行完以上安装,在/etc/init.d下会修改redis_6379名称并加入系统服务[root@node4 utils]# cd /etc/init.d/[root@node4 init.d]# mv redis_6379 redisd[root@node4 init.d]# chkconfig --add redisd
#检查加入系统状态,3,4,5为开,就是开机自动启动[root@node4 init.d]# chkconfig --list

# 在node4节点上编辑profile文件,vim /etc/profileexport REDIS_HOME=/software/redisexport PATH=$PATH:$REDIS_HOME/bin
#使环境变量生效source /etc/profile
后期每次开机启动都会自动启动 Redis,也可以使用以下命令手动启动|停止 redis
#启动redis[root@node4 init.d]# service redisd start
#停止redis[root@node4 init.d]# redis-cli shutdown
#进入redis客户端[root@node4 ~]# redis-cli
#切换1号库,并插入key127.0.0.1:6379> select 1127.0.0.1:6379[1]> hset rediskey zhagnsan 100
#查看所有key并获取key值127.0.0.1:6379[1]> keys *127.0.0.1:6379[1]> hgetall rediskey
#删除指定key127.0.0.1:6379[1]> del ’rediskey’
这里选择 Flink 的版本为 1.11.6,原因是 1.11.6 与 Iceberg 的整合比较稳定。
Flink 搭建节点分布如下:
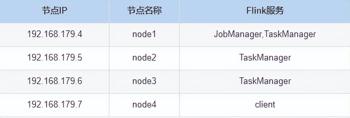
具体搭建步骤如下:
将 Flink 的安装包上传到 node1 节点/software 下并解压:
[root@node1 software]# tar -zxvf ./flink-1.11.6-bin-scala_2.11.tgz
在 node1 节点上进入到 Flink conf 目录下,配置 flink-conf.yaml 文件,内容如下:
#进入flink-conf.yaml目录[root@node1 conf]# cd /software/flink-1.11.6/conf/
#vim编辑flink-conf.yaml文件,配置修改内容如下jobmanager.rpc.address: node1taskmanager.numberOfTaskSlots: 3
其中:taskmanager.numberOfTaskSlot 参数默认值为 1,修改成 3。表示数每一个 TaskManager 上有 3 个 Slot。
在 node1 节点上配置 $FLINK_HOME/conf/workers 文件,内容如下:
node1
node2
node3
[root@node1 software]# scp -r ./flink-1.11.6 node2:/software/[root@node1 software]# scp -r ./flink-1.11.6 node3:/software/
#注意,这里发送到node4,node4只是客户端[root@node1 software]# scp -r ./flink-1.11.6 node4:/software/
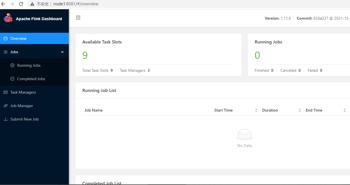
#在node1节点中,启动Flink集群[root@node1 ~]# cd /software/flink-1.11.6/bin/[root@node1 bin]# ./start-cluster.sh
http://node1:8081,进入页面如下:
在基于 Yarn 提交 Flink 任务时需要将 Hadoop 依赖包“flink-shaded-hadoop-2-uber-2.8.3-10.0.jar”放入 flink 各个节点的 lib 目录中(包括客户端)。
这里搭建 Flume 的版本为 1.9.0 版本,Flume 搭建使用单机模式,节点分配如下:

Flume 的搭建配置步骤如下:
[root@ node5 software]# tar -zxvf ./apache-flume-1.9.0-bin.tar.gz
#修改 /etc/profile文件,在最后追加写入如下内容,配置环境变量:[root@node5 software]# vim /etc/profileexport FLUME_HOME=/software/apache-flume-1.9.0-binexport PATH=$FLUME_HOME/bin:$PATH
#保存以上配置文件并使用source命令使配置文件生效[root@node5 software]# source /etc/profile
经过以上两个步骤,Flume 的搭建已经完成,至此,Flume 的搭建完成,我们可以使用 Flume 进行数据采集。
这里搭建 Maxwell 的版本为 1.28.2 版本,节点分配如下:

此项目主要使用 Maxwell 来监控业务库 MySQL 中的数据到 Kafka,Maxwell 原理是通过同步 MySQL binlog 日志数据达到同步 MySQL 数据的目的。Maxwell 不支持高可用搭建,但是支持断点还原,可以在执行失败时重新启动继续上次位置读取数据,此外安装 Maxwell 前需要开启 MySQL binlog 日志,步骤如下:
[root@node2 ~]# mysql -u root -p123456mysql> show variables like ’log_%’;
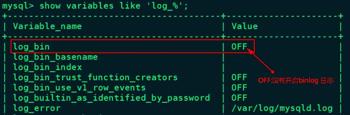
在/etc/f 文件中[mysqld]下写入以下内容:
[mysqld]
# 随机指定一个不能和其他集群中机器重名的字符串,配置 MySQL replaction 需要定义
server-id=123
#配置 binlog 日志目录,配置后会自动开启 binlog 日志,并写入该目录
log-bin=/var/lib/mysql/mysql-bin
# 选择 ROW 模式
binlog-format=ROW
[root@node2 ~]# service mysqld restart[root@node2 ~]# mysql -u root -p123456mysql> show variables like ’log_%’;
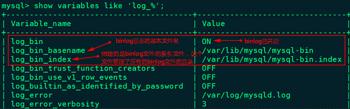
这里 maxwell 安装版本选择 1.28.2,选择 node3 节点安装,安装 maxwell 步骤如下:
[root@node3 ~]# cd /software/[root@node3 software]# tar -zxvf ./maxwell-1.28.2.tar.gz
Maxwell 同步 mysql 数据到 Kafka 中需要将读取的 binlog 位置文件及位置信息等数据存入 MySQL,所以这里创建 maxwell 数据库,及给 maxwell 用户赋权访问其他所有数据库。
mysql> CREATE database maxwell;mysql> CREATE USER ’maxwell’@’%’ IDENTIFIED BY ’maxwell’;mysql> GRANT ALL ON maxwell.* TO ’maxwell’@’%’;mysql> GRANT SELECT, REPLICATION CLIENT, REPLICATION SLAVE ON *.* TO ’maxwell’@’%’;mysql> flush privileges;
node3 节点进入“/software/maxwell-1.28.2”,修改“config.properties.example”为“config.properties”并配置:
producer=kafkakafka.bootstrap.servers=node1:9092,node2:9092,node3:9092kafka_topic=test-topic#设置根据表将binlog写入Kafka不同分区,还可指定:[database, table, primary_key, transaction_id, thread_id, column]producer_partition_by=table
#mysql 节点host=node2#连接mysql用户名和密码user=maxwellpassword=maxwell
#指定maxwell 当前连接mysql的实例id,这里用于全量同步表数据使用client_id=maxwell_first
注意:以上参数也可以在后期启动 maxwell 时指定参数方式来设置。
[root@node1 bin]# ./kafka-topics.sh --zookeeper node3:2181,node4:2181,node5:2181 --create --topic test-topic --partitions 3 --replication-factor 3
[root@node2 bin]# cd /software/kafka_2.11-0.11/[root@node2 bin]# ./kafka-console-consumer.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --topic test-topic
[root@node3 ~]# cd /software/maxwell-1.28.2/bin[root@node3 bin]# maxwell --config ../config.properties.
注意以上启动也可以编写脚本:
#startMaxwell.sh 脚本内容:/software/maxwell-1.28.2/bin/maxwell --config /software/maxwell-1.28.2/config.properties > ./log.txt 2>&1 &
修改执行权限:
chmod +x ./start_maxwell.sh
注意:这里我们可以通过 Maxwell 将 MySQL 业务库中所有 binlog 变化数据监控到 Kafka test-topic 中,在此项目中我们将 MySQL binlog 数据监控到 Kafka 中然后通过 Flink 读取对应 topic 数据进行处理。
mysql> create database testdb;mysql> use testdb;mysql> create table person(id int,name varchar(255),age int);mysql> insert into person values (1,’zs’,18);mysql> insert into person values (2,’ls’,19);mysql> insert into person values (3,’ww’,20);
可以看到在监控的 kafka test-topic 中有对应的数据被同步到 topic 中:

这里以 MySQL 表 testdb.person 为例将全量数据导入到 Kafka 中,可以通过配置 Maxwell,使用 Maxwell bootstrap 功能全量将已经存在 MySQL testdb.person 表中的数据导入到 Kafka,操作步骤如下:
#启动Maxwell[root@node3 ~]# cd /software/maxwell-1.28.2/bin[root@node3 bin]# maxwell --config ../config.properties
#启动maxwell-bootstrap全量同步数据[root@node3 ~]# cd /software/maxwell-1.28.2/bin[root@node3 bin]# ./maxwell-bootstrap --database testdb --table person --host node2 --user maxwell --password maxwell --client_id maxwell_first --where "id>0"
执行之后可以看到对应的 Kafka test-topic 中将表 testdb.person 中的数据全部导入一遍
这里 clickhouse 的版本选择 21.9.4.35,clickhouse 选择分布式安装,clickhouse 节点分布如下:
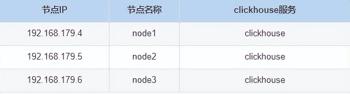
clickhouse 详细安装步骤如下:
这里选择 node1、node2,node3 三台节点,上传安装包,分别在每台节点上执行如下命令安装 clickhouse:
rpm -ivh ./mon-static-21.9.4.35-2.x86_64.rpm#注意在安装以下rpm包时,让输入密码,可以直接回车跳过rpm -ivh ./clickhouse-server-21.9.4.35-2.noarch.rpmrpm -ivh ./clickhouse-client-21.9.4.35-2.noarch.rpm
搭建 clickhouse 集群时,需要使用 Zookeeper 去实现集群副本之间的同步,所以这里需要 zookeeper 集群,zookeeper 集群安装后可忽略此步骤。
在每台 clickhouse 节点中配置/etc/clickhouse-server/config.xml 文件第 164 行,把以下对应配置注释去掉,如下:
<listen_host>::1</listen_host>#注意每台节点监听的host名称配置当前节点host,需要强制保存wq!<listen_host>node1</listen_host>
在 node1、node2、node3 节点上/etc/clickhouse-server/config.d 路径下下配置 metrika.xml 文件,默认 clickhouse 会在/etc 路径下查找 metrika.xml 文件,但是必须要求 metrika.xml 上级目录拥有者权限为 clickhouse ,所以这里我们将 metrika.xml 创建在/etc/clickhouse-server/config.d 路径下,config.d 目录的拥有者权限为 clickhouse。
在 metrika.xml 中我们配置后期使用的 clickhouse 集群中创建分布式表时使用 3 个分片,每个分片有 1 个副本,配置如下:
vim /etc/clickhouse-server/config.d/metrika.xml
<yandex> <remote_servers> <clickhouse_cluster_3shards_1replicas> <shard> <internal_replication>true</internal_replication> <replica> <host>node1</host> <port>9000</port> </replica> </shard> <shard> <internal_replication>true</internal_replication> <replica> <host>node2</host> <port>9000</port> </replica> </shard> <shard> <internal_replication>true</internal_replication> <replica> <host>node3</host> <port>9000</port> </replica> </shard> </clickhouse_cluster_3shards_1replicas> </remote_servers> <zookeeper> <node index="1"> <host>node3</host> <port>2181</port> </node> <node index="2"> <host>node4</host> <port>2181</port> </node> <node index="3"> <host>node5</host> <port>2181</port> </node> </zookeeper> <macros> <shard>01</shard> <replica>node1</replica> </macros> <networks> <ip>::/0</ip> </networks> <pression> <case> <min_part_size>10000000000</min_part_size> <min_part_size_ratio>0.01</min_part_size_ratio> <method>lz4</method> </case> </pression></yandex>
对以上配置文件中配置项的解释如下:
clickhouse 集群配置标签,固定写法。注意:这里与之前版本不同,之前要求必须以 clickhouse 开头,新版本不再需要。
配置 clickhouse 的集群名称,可自由定义名称,注意集群名称中不能包含点号。这里代表集群中有 3 个分片,每个分片有 1 个副本。
分片是指包含部分数据的服务器,要读取所有的数据,必须访问所有的分片。
副本是指存储分片备份数据的服务器,要读取所有的数据,访问任意副本上的数据即可。
分片,一个 clickhouse 集群可以分多个分片,每个分片可以存储数据,这里分片可以理解为 clickhouse 机器中的每个节点,1 个分片只能对应 1 服务节点。这里可以配置一个或者任意多个分片,在每个分片中可以配置一个或任意多个副本,不同分片可配置不同数量的副本。如果只是配置一个分片,这种情况下查询操作应该称为远程查询,而不是分布式查询。
每个分片的副本,默认每个分片配置了一个副本。也可以配置多个,副本的数量上限是由 clickhouse 节点的数量决定的。如果配置了副本,读取操作可以从每个分片里选择一个可用的副本。如果副本不可用,会依次选择下个副本进行连接。该机制利于系统的可用性。
默认为 false,写数据操作会将数据写入所有的副本,设置为 true,写操作只会选择一个正常的副本写入数据,数据的同步在后台自动进行。
配置的 zookeeper 集群,注意:与之前版本不同,之前版本是“zookeeper-servers”。
区分每台 clickhouse 节点的宏配置,macros 中标签代表当前节点的分片号,标签代表当前节点的副本号,这两个名称可以随意取,后期在创建副本表时可以动态读取这两个宏变量。注意:每台 clickhouse 节点需要配置不同名称。
这里配置 ip 为“::/0”代表任意 IP 可以访问,包含 IPv4 和 IPv6。
注意:允许外网访问还需配置/etc/clickhouse-server/config.xml 参照第三步骤。
MergeTree 引擎表的数据压缩设置,min_part_size:代表数据部分最小大小。min_part_size_ratio:数据部分大小与表大小的比率。method:数据压缩格式。
注意:需要在每台 clickhouse 节点上配置 metrika.xml 文件,并且修改每个节点的 macros 配置名称。
#node2节点修改metrika.xml中的宏变量如下: <macros> <shard>02</replica> <replica>node2</replica> </macros>
#node3节点修改metrika.xml中的宏变量如下: <macros> <shard>03</replica> <replica>node3</replica> </macros>
首先启动 zookeeper 集群,然后分别在 node1、node2、node3 节点上启动 clickhouse 服务,这里每台节点和单节点启动一样。启动之后,clickhouse 集群配置完成。
#每台节点启动Clickchouse服务service clickhouse-server start
#每台节点查看clickhouse服务状态service clickhouse-server status
#每台节点重启clickhouse服务service clickhouse-server restart
#每台节点关闭Clikchouse服务service clickhouse-server stop
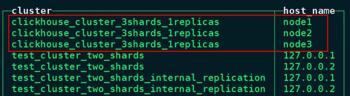
在 node1、node2、node3 任意一台节点进入 clickhouse 客户端,查询集群配置:
#选择三台clickhouse任意一台节点,进入客户端clickhouse-client #查询集群信息,看到下图所示即代表集群配置成功。node1 :) select * from system.clusters;

查询集群信息,也可以使用如下命令
node1 :) select cluster,host_name from system.clusters;
#在clickhouse node1节点创建mergeTree表 mtcreate table mt(id UInt8,name String,age UInt8) engine = MergeTree() order by (id);
#向表 mt 中插入数据insert into table mt values(1,’zs’,18),(2,’ls’,19),(3,’ww’,20);
#查询表mt中的数据select * from mt;
以上就是湖仓一体电商项目所有基础环境的搭建,希望对大家有帮助,下期会带来项目开发和实操,敬请期待吧
以上就是关于gg修改器root框架_gg修改器框架免root版中文的全部内容,游戏大佬们学会了吗?

gg大玩家修改器要root,下载gg大玩家修改器,畅享游戏乐趣 分类:免root版 2,619人在玩 在游戏中提升自己的实力是每个游戏爱好者都追求的目标,但有时候我们需要一些辅助工具来帮助我们更快地达成这个目标。GG大玩家修改器是这样一款软件,它可以让你在游戏中获得更多的……
下载
gg修改器免root版安全,下载gg修改器免root版安全,畅玩游戏 分类:免root版 4,944人在玩 如果您是一名游戏爱好者,那么一定会遇到一些困扰,例如游戏内的物品或角色需要付费购买,升级过程缓慢等等。为了解决这些问题,现在有许多软件可以帮助您轻松获取游戏内的资源和提……
下载
消消乐gg修改器免root_GG修改器怎么修改开心消消乐 分类:免root版 4,695人在玩 各位游戏大佬大家好,今天小编为大家分享关于消消乐gg修改器免root_GG修改器怎么修改开心消消乐的内容,轻松修改游戏数据,赶快来一起来看看吧。 提到开心消消乐这款小游戏,相信……
下载
gg修改器 免root应用,下载一个强大的gg修改器免root应用 分类:免root版 2,390人在玩 如果你是一名游戏爱好者,你一定会遇到这样的问题:某些游戏中需要付费才能获得更多的游戏币或者道具,但是你并不愿意花费大量的时间和金钱去获取它们。而现在,一个免费的工具——gg……
下载
华为 gg修改器免root,华为 GG修改器免Root一个能够为你带来无限畅玩的神器 分类:免root版 2,623人在玩 如果你是一名游戏爱好者,你一定会遇到各种各样的游戏难关和挑战。这时候,一个好用的修改器就可以解决你的所有问题。而今天,我们要为大家介绍的就是华为GG修改器免Root版,它可以……
下载
无root开GG修改器脚本_gg脚本免root 分类:免root版 6,314人在玩 各位游戏大佬大家好,今天小编为大家分享关于无root开GG修改器脚本_gg脚本免root的内容,轻松修改游戏数据,赶快来一起来看看吧。 近期很多朋友在使用群晖系统时把windows系统硬盘……
下载
gg修改器如何root,下载 GG修改器,轻松Root你的设备 分类:免root版 4,703人在玩 GG修改器是一款非常方便的工具,为用户提供了简单快捷的root方法。它不仅使用起来非常容易,而且还可以让用户在短时间内完成root操作。 快速Root你的设备 使用GG修改器,您可以轻……
下载
GG修改器免root游戏_gg免root游戏修改器教程 分类:免root版 6,483人在玩 各位游戏大佬大家好,今天小编为大家分享关于GG修改器免root游戏_gg免root游戏修改器教程的内容,轻松修改游戏数据,赶快来一起来看看吧。 随着现在手游行业的发展,在手机平台玩……
下载
gg修改器无root版本,下载推荐:gg修改器无root版本 分类:免root版 1,772人在玩 如果您曾经使用过Android手机,那么可能会遇到一些需要通过修改器来解决的问题。然而,很多修改器都需要root权限,这对于不熟悉技术的用户来说是非常困难的。幸运的是,现在有一个……
下载
叉叉酷玩gg修改器root_叉叉助手gg修改器 分类:免root版 5,437人在玩 各位游戏大佬大家好,今天小编为大家分享关于叉叉酷玩gg修改器root_叉叉助手gg修改器的内容,轻松修改游戏数据,赶快来一起来看看吧。 肖洪涛是水果O2O公司调果师CEO,曾经从事公……
下载