各位游戏大佬大家好,今天小编为大家分享关于怎样获取gg修改器root_怎么使用GG修改器?的内容,轻松修改游戏数据,赶快来一起来看看吧。
文|Bruce 得物技术
当前我们微服务容器化部署JVM 实例很多,常常需要进行JVM heap dump analysis,为了提升JVM 问题排查效率,得物技术保障团队研究了JVM内存Dump 原理与设计开发了JVM 内存在线分析。
常见的JVM heap dump analysis 工具如: MAT,JProfile,最常用的功能是大对象分析。功能上本地分析工具更全面,在微服务架构下,成千上万的实例当需要一次分析的时候,于是我们思考如何提供更方便更快的在线分析方便研发人员快速排障。
|
流程 |
传统 |
在线分析 |
相比 |
|
hprof 获取 |
jmap |
jmap |
相同 |
|
hprof 传输 |
1.上传ftp或对象存储。 2.生产环境涉及跨网脱敏。 3.跨网下载。 |
内网OSS(对象存储)传输。 |
目前jvm 基本进入G1 大内存时代。越大内存dump 效果越明显耗时降低(100倍耗时降低)为大规模dump分析打下基础。 |
|
hprof 分析 |
本地MAT 、JProfiler等分析工具 |
在线分析、在线分析报告 |
优点:
不足:
|
首先我们快速过一下Java 的内存模型, 这部分不必深入,稍微了解不影响第三部分 JVM 内存分析原理。可回过头来再看。
JVM 内存模型可以从共享和非共享理解,也可以从 stack,heap 理解。GC 主要作用于 heap 区, stack 的内存存在系统内存。
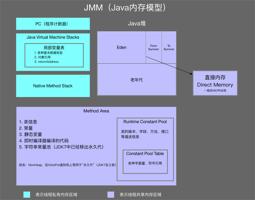
Java 程序运行起来后,JVM 会把它所管理的内存划分为若干个不同的数据区域。其中一些数据区是在 Java 虚拟机启动时创建的,只有在 Java 虚拟机退出时才会销毁。其他数据区是每个线程。每线程数据区在创建线程时创建,并在线程退出时销毁。JVM 的数据区是逻辑内存空间,它们可能不是连续的物理内存空间。下图显示了 JVM 运行时数据区域:
JVM 可以同时支持多个执行线程。每个 JVM 线程都有自己的 pc(程序计数器)寄存器。如果当前方法是 native方法则PC值为 undefined, 每个CPU 都有一个 PC,一般来说每一次指令之后,PC 值会增加,指向下一个操作指令的地址。JVM 使用PC 保持操作指令的执行顺序,PC 值实际上就是指向方法区(Method Area) 的内存地址。
每个 JVM 线程都有一个私有 JVM Stack(堆栈), 用于存储 Frames(帧)。JVM Stack的每一Frame(帧)都存储当前方法的局部变量数组、操作数堆栈和常量池引用。
一个 JVM Stack可能有很多Frame(帧),因为在线程的任何方法完成之前,它可能会调用许多其他方法,而这些方法的帧也存储在同一个 JVM Stack(堆栈)中。
JVM Stack 是一个先进后出(LIFO)的数据结构,所以当前的执行方法位于栈顶,每一个方法开始执行时返回、或抛出一个未捕获的异常,则次frame 被移除。
JVM Stack 除了压帧和弹出帧之外,JVM 堆栈从不直接操作,所以帧可能是堆分配的。JVM 堆栈的内存不需要是连续的。
Native 基本为C/C++ 本地函数,超出了Java 的范畴,就不展开赘述了。接入进入共享区域Heap 区。
JVM 有一个在所有 JVM 线程之间共享的堆。堆是运行时数据区,从中分配所有类实例和数组的内存。
堆是在虚拟机启动时创建的。对象的堆存储由自动存储管理系统(称为垃圾收集器)回收;对象永远不会被显式释放。JVM 没有假设特定类型的自动存储管理系统,可以根据实现者的系统要求选择存储管理技术。堆的内存不需要是连续的。
JVM 有一个在所有 JVM 线程之间共享的方法区。方法区类似于常规语言编译代码的存储区,或类似于操作系统进程中的“文本”段。它存储每个类的结构,例如运行时常量轮询、字段和方法数据,以及方法和构造函数的代码,包括在类和实例初始化和接口初始化中使用的特殊方法。
Method 区域是在虚拟机启动时创建的。尽管方法区在逻辑上是堆的一部分,但简单的实现可能会选择不进行垃圾收集或压缩它。方法区可以是固定大小,也可以根据需要进行扩展。方法区的内存不需要是连续的。
运行时常量池是方法区的一部分。Claas 文件中除了有类的版本、字段、方法、接口等描述信息外,还有一项信息是常量池(Constant Pool Table),用于存放编译期生成各种字面量和符号引用,这部分内容将在类加载后进入方法区的运行时常量池中存放。
Java 程序最终运行的主体是线程,那么JVM 运行时数据区可以按线程间是否共享来划分:
Pre-Threads:
JVM System Threads:
如果你使用jconsole或者其他任何debug工具,有可能你会发现有大量的线程在后台运行。这些后台线程随着main线程的启动而启动,即,在执行public static void main(String[])后,或其他main线程创建的其他线程,被启动后台执行。
Hotspot JVM 主要的后台线程包括:
Program Counter (PC)
当前操作指令或opcode的地址指针,如果当前方法是本地方法,则PC值为undefined。每个CPU都有一个PC,一般来说,每一次指令之后,PC值会增加,指向下一个操作指令的地址。JVM使用PC保持操作指令的执行顺序,PC值实际上就是指向方法区(Method Area)中的内存地址。
Stack
每一个线程都拥有自己的栈(Stack),用于在本线程中正在执行的方法。栈是一个先进后出(LIFO)的数据结构,所以当前的执行方法位于栈顶。每一个方法开始执行时,一个新的帧(Frame)被创建(压栈),并添加到栈顶。当方法正常执行返回,或方法执行时抛出一个未捕获的异常,则此帧被移除(弹栈)。栈,除了压栈和弹栈操作外,不会被执行操作,因此,帧对象可以被分配在堆(Heap)内存中,并且不需要分配连续内存。
Native Stack
不是所有的JVM都支持本地方法,然而,基本上都会为每个线程,创建本地方法栈。如果JVM使用C-Linkage模型,实现了JNI(Java Native Invocation),那么本地栈就会是一个C语言的栈。在这种情况下,本地栈中的方法参数和返回值顺序将和C语言程序完全一致。一个本地的方法一般可以回调JVM中的Java方法(依据具体JVM实现而定)。这样的本地方法调用Java方法一般会使用Java栈实现,当前线程将从本地栈中退出,在Java栈中创建一个新的帧。
Stack Restrictions
栈可以使一个固定大小或动态大小。如果一个线程请求超过允许的栈空间,允许抛出StackOverflowError。如果一个线程请求创建一个帧,而没有足够内存时,则抛出OutOfMemoryError。
Frame
每一个方法被创建的时候都会创建一个 frame,每个 frame 包含以下信息:
Local Variables Array
本地变量数组包含所有方法执行过程中的所有变量,包括this引用,方法参数和其他定义的本地变量。对于类方法(静态方法),方法参数从0开始,然后对于实例方法,参数数据的第0个元素是this引用。
本地变量包括:
|
基本数据类型 |
bits |
bytes |
|
boolean |
32 |
4 |
|
byte |
32 |
4 |
|
char |
32 |
4 |
|
long |
64 |
8 |
|
short |
32 |
4 |
|
int |
32 |
4 |
|
float |
32 |
4 |
|
double |
64 |
8 |
|
reference |
32 |
4 |
|
reference |
32 |
4 |
所有类型都占用一个数据元素,除了long和double,他们占用两个连续数组元素。(这两个类型是64位的,其他是32位的)
Operand Stack
在执行字节代码指令过程中,使用操作对象栈的方式,与在本机CPU中使用通用寄存器相似。大多数JVM的字节码通过压栈、弹栈、复制、交换、操作执行这些方式来改变操作对象栈中的值。因此,在本地变量数组中和操作栈中移动复制数据,是高频操作。
Frame 被创建时,操作栈是空的,操作栈的每个项可以存放JVM 的各种类型,包括 long/double。操作栈有一个栈深,long/double 占用2个栈深,操作栈调用其它有返回结果的方法时,会把结果push 到栈上。
下面举例说明,通过操作对象栈,将一个简单的变量赋值为0.
Java:
int i;
编译后得到以下字节码:
0: iconst_0 // 将0压到操作对象栈的栈顶
1: istore_1 // 从操作对象栈中弹栈,并将值存储到本地变量1中
Dyanmic Linking
每个帧都包含一个引用指针,指向运行时常量池。这个引用指针指向当前被执行方法所属对象的常量池。
当Java Class被编译后,所有的变量和方法引用都利用一个引用标识存储在class的常量池中。一个引用标识是一个逻辑引用,而不是指向物理内存的实际指针。JVM实现可以选择何时替换引用标识,例如:class文件验证阶段、class文件加载后、高频调用发生时、静态编译链接、首次使用时。然后,如果在首次链接解析过程中出错,JVM不得不在后续的调用中,一直上报相同的错误。使用直接引用地址,替换属性字段、方法、类的引用标识被称作绑定(Binding),这个操作只会被执行一次,因为引用标识都被完全替换掉,无法进行二次操作。如果引用标识指向的类没有被加载(resolved),则JVM会优先加载(load)它。每一个直接引用,就是方法和变量的运行时所存储的相对位置,也就是对应的内存偏移量。
Share Between Threads
Heap
堆用作为class实例和数据在运行时分配存储空间。数组和对象不能被存储在栈中,因为帧空间在创建时分配,并不可改变。帧中只存储对象或者数组的指针引用。不同于原始类型,和本地变量数组的引用,对象被存储在堆中,所以当方法退出时,这些对象不会被移除。这些对象只会通过垃圾回收来移除。
Memory Management
对象和数据不会被隐形的回收,只有垃圾回收机制可以释放他们的内存。
典型的运行流程如下:
a.新的对象和数组使用年轻代内存空间进行创建
b.年轻代GC(Minor GC/Young GC)在年轻代内进行垃圾回收。不满足回收条件(依然活跃)的对象,将被移动从eden区移动到survivor区。
c.老年代GC(Major GC/Full GC)一般会造成应用的线程暂停,将在年轻代中依然活跃的对象,移动到老年代Old Generation (Tenured Generation)。
d.Permanent Generation区的GC会随着老年代GC一起运行。其中任意一个区域在快用完时,都会触发GC操作。
Non-Heap Memory
属于JVM内部的对象,将在非堆内存区创建。
非堆内存包括:
Just In Time (JIT) Compilation
Java字节码通过解释执行,然后,这种方式不如JVM使用本地CPU直接执行本地代码快。为了提供新能,Oracle Hotspot虚拟机寻找热代码(这些代码执行频率很高),把他们编译为本地代码。本地代码被存储在非堆的code cache区内。通过这种方式,Hotspot VM通过最适当的方式,开销额外的编译时间,提高解释执行的效率。
java运行时数据区域可以按线程每个内部共享和所有线程是否共享来理解。
Method Area
方法区中保存每个类的的详细信息,如下:
Numeric constants
Field references
Method References
Attributes
Per field
Name
Type
Modifiers
Attributes
Per method
Name
Return Type
Parameter Types (in order)
Modifiers
Attributes
Per method
Bytecodes
Operand stack size
Local variable size
Local variable table
Exception table
Per exception handler
Start point
End point
PC offset for handler code
Constant pool index for exception class being caught
Java:
ClassFile {
u4 magic;
u2 minor_version;
u2 major_version;
u2 constant_pool_count;
cp_info contant_pool[constant_pool_count – 1];
u2 access_flags;
u2 this_class;
u2 super_class;
u2 interfaces_count;
u2 interfaces[interfaces_count];
u2 fields_count;
field_info fields[fields_count];
u2 methods_count;
method_info methods[methods_count];
u2 attributes_count;
attribute_info attributes[attributes_count];
}
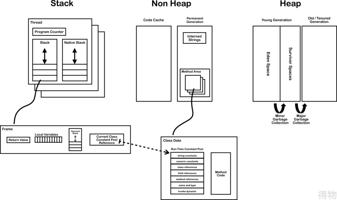
随着JDK 版本和不同厂商的实现,JVM 内部模型有些细微的不同,如JDK 1.8 永久代 -> 元数据空间 等等,大体的 JVM 模型还是差不多。
JVM 内存分析的总目的是希望能够清楚 JVM 各个部分的情况,然后完成TOP N 统计,给出一份 分析报告,方便快递定位判断问题根因。
我们一般使用 jmap 对正在运行的java 进程做 内存 dump形成 Hprof 文件,然后下载到本地离线分析。那么我们在线分析工具面临的第一个问题就是对 hprof 文件的解析。
当我们使用 jmap 生成 Hprof 文件,因为它是二进制文件直接打开如下:
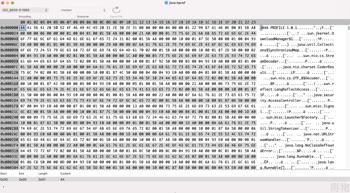
这种文件非常紧凑没有“分隔符”错一个字节,就会失败,通过 jvm 源码可以查到其有数据结构:
https://hg.openjdk.java.net/jdk/jdk/file/ee1d592a9f53/src/hotspot/share/services/heapDumper.cpp#l62
c++:
HPRO_FILE{
header "JAVA PROFILE 1.0.2" (以0为结束)
u4 标识符大小,标识符用于表示 ,UTF8 Strings、Objects、Stack traces等,
该值通常与机器CPU位数相关,32位是4,64位是8。
u4 high word
u4 low word 高位+地位 共同表达从 1970年以来的毫秒数,得到 dump 时的时间
[record]* record 数组
}
Bash:
Record {
u1 Tag
u4 微妙,记录从 header 得到的时间以来
[u1]* bytes 数组,代表该 record 的内容
}
Record tags 列表比较长,可直接看在线源码:
https://hg.openjdk.java.net/jdk/jdk/file/ee1d592a9f53/src/hotspot/share/services/heapDumper.cpp#l87
Bash:
TAG BODY notes
----------------------------------------------------------
HPROF_UTF8 a UTF8-encoded name
id name ID
[u1]* utf8 字符 (no trailing zero)
HPROF_LOAD_CLASS 新加载 class
u4 class serial number (class 编号)
id class object ID
u4 stack trace serial number(堆栈跟踪序列号)
id class name ID
HPROF_UNLOAD_CLASS 卸载 class
u4 class serial_number(class 编号)
HPROF_FRAME a Java stack frame
id stack frame ID
id method name ID
id method signature ID
id source file name ID
u4 class serial number
i4 line number. >0: normal 正常
-1: unknown 未知
-2: compiled method 编译方法
-3: native method 本地方法
HPROF_TRACE a Java stack trace
u4 stack trace serial number (stack trace 编号)
u4 thread serial number (thread 编号)
u4 number of frames(frames 数量)
[id]* stack frame IDs (堆栈帧 id)
HPROF_ALLOC_SITES gc 之后,heap 分配的 site 点
u2 flags 0x0001: 增量 与 全量
0x0002: 按需分配与实时排序
0x0004: 是否强制 gs
u4 cutoff ratio (截止率)
u4 total live bytes
u4 total live instances
u8 total bytes allocated
u8 total instances allocated
u4 number of sites that follow
[u1 is_array: 0: normal object
2: object array
4: boolean array
5: char array
6: float array
7: double array
8: byte array
9: short array
10: int array
11: long array
u4 class serial number (序列号,启动时可能为0)
u4 stack trace serial number (stack trace 序列号)
u4 number of bytes alive (活着的字节数)
u4 number of instances alive (活着的实例数)
u4 number of bytes allocated (分配的字节数)
u4]* number of instance allocated(分配的实例数)
HPROF_START_THREAD 一个新的线程
u4 thread serial number (thread 序列号)
id thread object ID
u4 stack trace serial number
id thread name ID
id thread group name ID
id thread group parent name ID
HPROF_END_THREAD 一个终止线程
u4 thread serial number
HPROF_HEAP_SUMMARY heap 概要
u4 total live bytes
u4 total live instances
u8 total bytes allocated
u8 total instances allocated
HPROF_CPU_SAMPLES a set of sample traces of running threads
u4 total number of samples
u4 # of traces
[u4 # of samples
u4]* stack trace serial number
HPROF_CONTROL_SETTINGS the settings of on/off switches
u4 0x00000001: alloc traces on/off
0x00000002: cpu sampling on/off
u2 stack trace depth
When the header is "JAVA PROFILE 1.0.2" a heap dump can optionally
be generated as a sequence of heap dump segments. This sequence is
terminated by an end record. The additional tags allowed by format
"JAVA PROFILE 1.0.2" are:
HPROF_HEAP_DUMP_SEGMENT denote a heap dump segment
[heap dump sub-records]*
The same sub-record types allowed by HPROF_HEAP_DUMP
HPROF_HEAP_DUMP_END denotes the end of a heap dump
HPROF_HEAP_DUMP 内容较多,单独从上面抽出来:
https://hg.openjdk.java.net/jdk/jdk/file/ee1d592a9f53/src/hotspot/share/services/heapDumper.cpp#l175
Bash:
HPROF_HEAP_DUMP 内存dump 真正存放数据的地方
[heap dump sub-records]*
有4中类型 sub-records:
u1 sub-record type
HPROF_GC_ROOT_UNKNOWN unknown root (未知 root)
id object ID
HPROF_GC_ROOT_THREAD_OBJ thread object
id thread object ID (通过 JNI新创建的可能为0)
u4 thread sequence number
u4 stack trace sequence number
HPROF_GC_ROOT_JNI_GLOBAL JNI global ref root (JNI 全局引用跟)
id object ID
id JNI global ref ID
HPROF_GC_ROOT_JNI_LOCAL JNI local ref
id object ID
u4 thread serial number
u4 frame # in stack trace (-1 表示 empty)
HPROF_GC_ROOT_JAVA_FRAME Java stack frame
id object ID
u4 thread serial number
u4 frame # in stack trace (-1 表示 empty)
HPROF_GC_ROOT_NATIVE_STACK Native stack (本地方法)
id object ID
u4 thread serial number
HPROF_GC_ROOT_STICKY_CLASS System class
id object ID
HPROF_GC_ROOT_THREAD_BLOCK Reference from thread block
id object ID
u4 thread serial number
HPROF_GC_ROOT_MONITOR_USED Busy monitor
id object ID
HPROF_GC_CLASS_DUMP class 对象的 dump
id class object ID
u4 stack trace serial number
id super class object ID
id class loader object ID
id signers object ID
id protection domain object ID
id reserved
id reserved
u4 instance size (in bytes)
u2 size of constant pool(常量池大小)
[u2, constant pool index,(常量池索引)
ty, type
2: object
4: boolean
5: char
6: float
7: double
8: byte
9: short
10: int
11: long
vl]* and value
u2 number of static fields
[id, static field name,
ty, type,
vl]* and value
u2 number of inst. fields (不包括 super)
[id, instance field name,
ty]* type
HPROF_GC_INSTANCE_DUMP 正常 object 实例的 dump
id object ID
u4 stack trace serial number
id class object ID
u4 number of bytes that follow
[vl]* instance field values (先是 class 的,然后 是 super 的,再 super 的 super ,这里只是这些字段值的 bytes,还需要按字段类型转换)
HPROF_GC_OBJ_ARRAY_DUMP dump of an object array
id array object ID
u4 stack trace serial number
u4 number of elements
id array class ID
[id]* elements
HPROF_GC_PRIM_ARRAY_DUMP dump of a primitive array
id array object ID
u4 stack trace serial number
u4 number of elements
u1 element type
4: boolean array
5: char array
6: float array
7: double array
8: byte array
9: short array
10: int array
11: long array
[u1]* elements
Bash:
enum tag {
// top-level records
HPROF_UTF8 = 0x01,
HPROF_LOAD_CLASS = 0x02,
HPROF_UNLOAD_CLASS = 0x03,
HPROF_FRAME = 0x04,
HPROF_TRACE = 0x05,
HPROF_ALLOC_SITES = 0x06,
HPROF_HEAP_SUMMARY = 0x07,
HPROF_START_THREAD = 0x0A,
HPROF_END_THREAD = 0x0B,
HPROF_HEAP_DUMP = 0x0C,
HPROF_CPU_SAMPLES = 0x0D,
HPROF_CONTROL_SETTINGS = 0x0E,
// 1.0.2 record types
HPROF_HEAP_DUMP_SEGMENT = 0x1C,
HPROF_HEAP_DUMP_END = 0x2C,
// field types
HPROF_ARRAY_OBJECT = 0x01,
HPROF_NORMAL_OBJECT = 0x02,
HPROF_BOOLEAN = 0x04,
HPROF_CHAR = 0x05,
HPROF_FLOAT = 0x06,
HPROF_DOUBLE = 0x07,
HPROF_BYTE = 0x08,
HPROF_SHORT = 0x09,
HPROF_INT = 0x0A,
HPROF_LONG = 0x0B,
// data-dump sub-records
HPROF_GC_ROOT_UNKNOWN = 0xFF,
HPROF_GC_ROOT_JNI_GLOBAL = 0x01,
HPROF_GC_ROOT_JNI_LOCAL = 0x02,
HPROF_GC_ROOT_JAVA_FRAME = 0x03,
HPROF_GC_ROOT_NATIVE_STACK = 0x04,
HPROF_GC_ROOT_STICKY_CLASS = 0x05,
HPROF_GC_ROOT_THREAD_BLOCK = 0x06,
HPROF_GC_ROOT_MONITOR_USED = 0x07,
HPROF_GC_ROOT_THREAD_OBJ = 0x08,
HPROF_GC_CLASS_DUMP = 0x20,
HPROF_GC_INSTANCE_DUMP = 0x21,
HPROF_GC_OBJ_ARRAY_DUMP = 0x22,
HPROF_GC_PRIM_ARRAY_DUMP = 0x23
}
现在我们知道 hprof 虽然是 二进制格式的文件,但其也有数据结构,就是一条一条 record 记录。那么解析就按照对应的格式来完成其格式解析。
核心解析伪代码:
Go:
for {
r, err := p.ParseRecord()
}
func (p *HProfParser) ParseRecord() (interface{}, error) {
if p.heapDumpFrameLeftBytes > 0 { // 处理 sub-record
return p.ParseSubRecord()
}
tag, err := p.reader.ReadByte()
if err != nil {
return nil, err
}
recordHeader, _ := p.parseHeaderRecord()
switch tag {
case TagString:
return p.parseUtf8String(recordHeader)
...
default:
return nil, fmt.Errorf("unknown record type: 0x%x", tag)
}
}
func (p *HProfParser) ParseSubRecord() (interface{}, error) {
tag, err := p.readByte()
if err != nil {
return nil, err
}
switch tag {
case TagGcRootUnknown:
return p.parseGcRootUnknown()
...
default:
return nil, fmt.Errorf("unknown heap dump record type: 0x%x", tag)
}
}
上面代码完成对 Hprof 文件的不停read bytes 并将其解析转换成 结构化的 record。当我们能完成对其转换成 record 记录之后,面临两个问题:一个存储问题,最简单直接存储在内存中,但这种方式依赖主机的物理内存,分析大内存dump 文件会受限制,一个是格式问题,最简单的是存储 record 的 json 格式,这种方式阅读性强,但弱点是数据量比较大,于是我们做了一下调研:
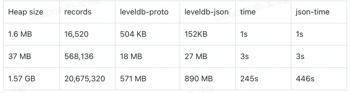
综合选择了 LSM-tree 数据结构类型的 KV 数据库leveldb 配合 proto3 进行二进制编码压缩。进过分析产出报告存入后台 mongo 。
当我们理解了 jvm 内存分布,理解并完成了 hprof 文件的解析、存储。那么剩下最后一个步完成对其分析,产出分析报告,这里我们举两个例子:1、线程分析 2、 大对象分析。
下面我们以下面这段代码做成 jar 运行,然后 jmap 生成 heap.hprof 文件进行分析。
Java:
# Main.Java
public class Main {
public static void main(String[] args) {
String[] aaa = new String[100000];
for (int i = 0; i < 100000; i++) {
aaa[i] = "aaa";
}
System.out.println("=============");
try {
Thread.sleep(300000);
} catch (Exception ee) {
ee.printStackTrace();
}
}
}
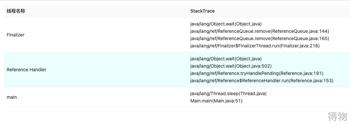
我们本地数据库最终得到的是大量的 record 记录,那么这些 record 之间的关联关系,以及如何使用我们通过几个例子初步了解一下。(jstack 能获得更详细的线程信息,从 Heap dump 也能获得线程信息哦),首先我们通过常用的三个线程来感受一下 record 的关系。
Java:
Root Thread Object:
object id: 33284953712
thread serial num: 5
stack trace serial num: 6
Instance Dump:
object id: 33284953712
stack trace serial num: 1
class object id: 33285008752
instance field values:
threadLocalRandomSecondarySeed = 0
threadLocalRandomProbe = 0
threadLocalRandomSeed = 0
uncaughtExceptionHandler = 0
blockerLock = 33284954824
blocker = 0
parkBlocker = 0
threadStatus = 225
tid = 1
nativeParkEventPointer = 0
stackSize = 0
inheritableThreadLocals = 0
threadLocals = 33284954176
inheritedAccessControlContext = 33284954136
contextClassLoader = 33285041480
group = 33284949288
target = 0
stillborn = false
daemon = false
single_step = false
eetop = 140312336961536
threadQ = 0
priority = 5
name = 33284954088
Instance Dump:
object id: 33284954088
stack trace serial num: 1
class object id: 33284980264
instance field values:
hash = 0
value = 33284954112
Primitive Array Dump:
object id: 33284954112
stack trace serial num: 1
number of elements: 4
element type: char
element 1: m
element 2: a
element 3: i
element 4: n
通过上面例子个跟踪我们基本能获得 虽然都是 record 但是其不同的类型代表不一样的信息,而将他们关联的东西其实就是上面 JVM 运行时数据区里面的描述对应。有 class –> object instance –> primitive Array 等等。这里需要读者理解 JVM Run-time Data Areas 以及 CLassFile 的数据结构,来完成 record 的关系。
伪代码:
Go:
func (j *Job) ParserHprofThread() error {
err := j.index.ForEachRootThreadObj(func(thread *hprofdata.GcRootThreadObject) error {
trace, _ := j.index.Trace(uint64(thread.StackTraceSequenceNumber))
if len(trace.StackFrameIds) != 0 {
instance, _ := j.index.Instance(thread.ThreadObjectId)
threadName := j.index.ProcessInstance(instance)
stackTrace := ""
for _, frameId := range trace.StackFrameIds {
frame, _ := j.index.Frame(frameId)
method_name, _ := j.index.String(frame.MethodNameId)
source_file_name, _ := j.index.String(frame.SourceFileNameId)
loadclass, _ := j.index.LoadedClass(frame.ClassSerialNumber)
className, _ := j.index.String(loadclass.ClassNameId)
stackStr := ""
if frame.LineNumber > 0 {
stackStr = fmt.Sprintf(" %s.%s(%s:%d)
",
className,
method_name, source_file_name, frame.LineNumber)
} else {
stackStr = fmt.Sprintf(" %s.%s(%s)
",
className,
method_name, source_file_name)
}
stackTrace += stackStr
}
heapThread := &HeapThread{
Id: thread.ThreadObjectId,
ThreadName: threadName,
ThreadStackTrace: stackTrace,
}
j.heapDump.Threads = append(j.heapDump.Threads, heapThread)
}
return nil
})
if err != nil {
return err
}
return nil
}
获得效果图:
大对象分析思路分别获得 Instance、 PrimitiveArray 、ObjectArray 这三种对象数据进行 TOP N 排序。
伪代码:
Go:
func (a *Analysis) DoAnalysis(identifierSize uint32) ([]*DumpArray, uint64) {
var allDumpVec []*DumpArray
var totalDataSize uint64
classesDumpVec, classTotalDataSize := a.analysisClassInstance(identifierSize)
allDumpVec = append(allDumpVec,classesDumpVec...)
totalDataSize = classTotalDataSize
sort.Sort(DumpArrayWrapper{allDumpVec, func(p, q *DumpArray) bool {
return q.TotalSize < p.TotalSize
}})
return allDumpVec, totalDataSize
}
func (a *Analysis) analysisClassInstance(identifierSize uint32) ([]*DumpArray, uint64) {
classesInstanceCounters := make(map[uint64]*ClassInstanceCounter)
_ = a.Index.ForEachInstance(func(instance *hprofdata.GcInstanceDump) error {
size := instance.DataSize + identifierSize + 8
counter := classesInstanceCounters[instance.ClassObjectId]
if counter != nil {
counter.addInstance(instance.ObjectId, uint64(size))
} else {
classesInstanceCounters[instance.ClassObjectId] = &ClassInstanceCounter{
arrayObjectIds: []uint64{instance.ObjectId},
Type: 0,
numberOfInstance: 1,
maxSizeSeen: uint64(size),
totalSize: uint64(size),
}
}
return nil
})
var totalDataSize uint64
var classesDumpVec []*DumpArray
pq := queue_helper.New()
for classId, counter := range classesInstanceCounters {
totalDataSize += counter.totalSize
className := a.getClassNameString(classId)
dumpArray := &DumpArray{
Str: className,
ArrayObjectIds: counter.arrayObjectIds,
Type: counter.Type,
NumberOfSize: counter.numberOfInstance,
MaxSizeSeen: counter.maxSizeSeen,
TotalSize: counter.totalSize,
}
pq.Insert(dumpArray,dumpArray.TotalSize)
if pq.Len() > 10 {
pq.Pop()
}
}
count := pq.Len()
for i := 0; i < count; i++ {
item,_ := pq.Pop()
array := item.(*DumpArray)
classesDumpVec = append(classesDumpVec,array)
}
sort.Sort(DumpArrayWrapper{classesDumpVec, func(p, q *DumpArray) bool {
return q.TotalSize < p.TotalSize
}})
return classesDumpVec,totalDataSize
}
效果图:

可以看见最大的对象就是 String 数组,与我们源码写的一致。
通过上面我们完成了对一个 jvm heap dump 文件的解析、存储、分析。于是我们更近一步完成工具平台化,支持在线分析、多JVM 同时分析、支持水平扩容、支持大内存dump 分析、在线开报告等等。
平台架构图:
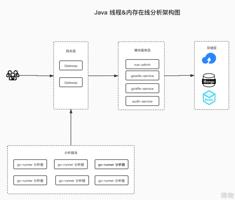
(整体上也是微服务架构,前面网关后面跟各个模块,分析器单独运行,这样可以支持多个并发分析任务。)
使用流程图:
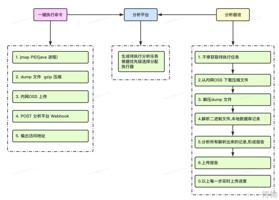
(对应用户来说我们提供了一键命令执行,这张图介绍一键命令背后的逻辑关系。)
成品效果图:
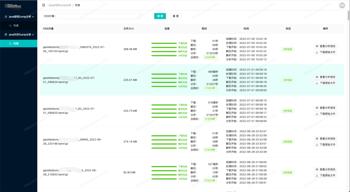
能看见各个分析任务的实时进度。

分析完成之后可查看详细分析报告。
本文主要介绍了得物技术保障团队在 Java 内存在线分析方案设计和落地的过程中遇到的问题以及解决方案,解决了研发人员对任何环境JVM实例进行快速内存Dump 和在线查看分析报告,免去一些列dump文件制作、下载、安装工具分析等等。
未来得物技术保障团队计划继续开发Java 线程分析,Java GC log 分析等等。形成对一个JVM 实例从内存、线程、GC 情况全方位分析,提升排查Java 应用性能问题效率。
Reference:
《Java 虚拟机规范(Java SE 8 版)》
《深入理解Java 虚拟机》
https://www./2020/06/19/jvm-runtime-data-areas/
https://wu-sheng.github.io/me/articles/JVMInternals.html
https://wu-sheng.github.io/me/articles/JVMInternals-p2.html
*文/Bruce
关注得物技术,每周一三五晚18:30更新技术干货
要是觉得文章对你有帮助的话,欢迎评论转发点赞~
以上就是关于怎样获取gg修改器root_怎么使用GG修改器?的全部内容,游戏大佬们学会了吗?
GG免root修改器推荐_gg修改器免root怎么用 分类:免root版 4,748人在玩 各位游戏大佬大家好,今天小编为大家分享关于GG免root修改器推荐_gg修改器免root怎么用的内容,轻松修改游戏数据,赶快来一起来看看吧。 肯定已经有许多动手能力强的值友将自己的……
下载
GG修改器root下载安装,下载和安装GG修改器root 分类:免root版 2,958人在玩 GG修改器root是一款非常实用的软件,它可以让用户在手机上修改游戏、应用程序以及系统设置等,从而满足个性化需求。如果你正在寻找一款好用的修改器软件,那么GG修改器root绝对值得……
下载
gg修改器root权限下载_gg修改器免root权限下载 分类:免root版 6,502人在玩 各位游戏大佬大家好,今天小编为大家分享关于gg修改器root权限下载_gg修改器免root权限下载的内容,轻松修改游戏数据,赶快来一起来看看吧。 刷机这个词汇, 距离现在的人真的太久……
下载
怎么打开gg修改器root权限_怎样给gg修改器root权限 分类:免root版 6,806人在玩 各位游戏大佬大家好,今天小编为大家分享关于怎么打开gg修改器root权限_怎样给gg修改器root权限的内容,轻松修改游戏数据,赶快来一起来看看吧。 考虑到“开发者选项”中的部分功能……
下载
gg修改器免root框_gg修改器免root框架怎么用 分类:免root版 4,640人在玩 各位游戏大佬大家好,今天小编为大家分享关于gg修改器免root框_gg修改器免root框架怎么用的内容,轻松修改游戏数据,赶快来一起来看看吧。 这篇博客我觉得讲得非常好,把好多我模糊……
下载
gg免root修改器方舟,下载gg免root修改器方舟,轻松修改游戏! 分类:免root版 4,524人在玩 现在越来越多的手机游戏需要进行Root权限才能够进行修改,但是Root操作却会很容易让手机变砖。这时候,有了gg免root修改器方舟,就可以轻松愉快地修改游戏啦! gg免root修改器方舟……
下载
无root用gg修改器框架,软件推荐:无root用gg修改器框架 分类:免root版 3,684人在玩 如果您是一名游戏爱好者,那么您可能知道GG修改器这个工具。它可以帮助你在游戏过程中修改一些参数,例如金币、经验值等等。但是,这个工具需要root权限才能正常运行,而有些用户由……
下载
怎么开启gg修改器root,下载最新版gg修改器root,轻松获取超级权限 分类:免root版 2,319人在玩 如果你需要更多的自由控制你的 Android 设备,那么你需要一个能够获取超级权限的工具。而 gg 修改器 root 就是这样一款强大的工具。它可以让你轻松地获取 root 权限,从而获取更多……
下载
平板gg修改器怎么root_平板gg修改器怎么用 分类:免root版 4,357人在玩 各位游戏大佬大家好,今天小编为大家分享关于平板gg修改器怎么root_平板gg修改器怎么用的内容,轻松修改游戏数据,赶快来一起来看看吧。 【PConline 静态体验】运行Android和iOS系……
下载
gg修改器root框架下载,软件下载 | GG修改器root框架下载 分类:免root版 4,826人在玩 | GG修改器root框架是一款非常实用的软件,它可以让用户在手机上轻松地进行修改和优化。无论是想要刷机、卡刷还是进行游戏内的修改,这个工具都能够帮助你快速完成。下面,我们就来……
下载