各位游戏大佬大家好,今天小编为大家分享关于不用root的gg修改器_gg修改器不需要root的内容,轻松修改游戏数据,赶快来一起来看看吧。
JVM 真的是学完忘。忘了学 因为很少去用 工作中很少接触 但是又是一个必须了解的都东西 复习整理必不可少
Java 源码通过 javac 编译为 Java 字节码 ,Java 字节码是 Java 虚拟机执行的一套代码格式,其抽象了计算机的基本操作。大多数指令只有一个字节,而有些操作符需要参数,导致多使用了一些字节。

JVM 的基本架构如上图所示,其主要包含三个大块:
在 JVM 中运行着许多线程,这里面有一部分是应用程序创建来执行代码逻辑的 应用线程,剩下的就是 JVM 创建来执行一些后台任务的 系统线程。
主要的系统线程有:
按照线程类型来分,在 JVM 内部有两种线程:
只要有任何的非守护线程在运行,Java程序也会继续运行。当该程序中所有的非守护线程都终止时,虚拟机实例将自动退出(守护线程随 JVM 一同结束工作)。
守护线程中不适合进行IO、计算等操作,因为守护线程是在所有的非守护线程退出后结束,这样并不能判断守护线程是否完成了相应的操作,如果非守护线程退出后,还有大量的数据没来得及读写,这将造成很严重的后果。
类加载器是 Java 运行时环境(Java Runtime Environment)的一部分,负责动态加载 Java 类到 Java 虚拟机的内存空间中。类通常是按需加载,即第一次使用该类时才加载。 由于有了类加载器,Java 运行时系统不需要知道文件与文件系统。每个 Java 类必须由某个类加载器装入到内存。
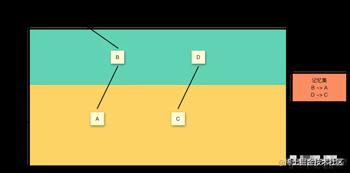
这个时候要进行 Young GC,要确定 C 是否被堆外引用,就需要遍历 Old Gen,这样的代价太大。所以 JVM 在进行对象引用的时候,会有个 记忆集(Remembered Set) 记录从 Old Gen 到 Young Gen 的引用关系,并把记忆集里的 Old Gen 作为 GC Root 来构建引用图。这样在进行 Young GC 时就不需要遍历 Old Gen。
但是使用记忆集也会有缺点:C & D 其实都可以进行回收,但是由于记忆集的存在,不会将 C 回收。这里其实有一点 空间换时间 的意思。不过无论如何,它依然确保了垃圾回收所遵循的原则:垃圾回收确保回收的对象必然是不可达对象,但是不确保所有的不可达对象都会被回收。
针对 HotSpot VM 的实现,它里面的 GC 其实准确分类只有两大种:
最简单的分代式GC策略,按 HotSpot VM 的 serial GC 的实现来看,触发条件是
并发 GC 的触发条件就不太一样。以 CMS GC 为例,它主要是定时去检查 Old Gen 的使用量,当使用量超过了触发比例就会启动一次 GC,对 Old Gen做并发收集。
DirectByteBuffer 的引用是直接分配在堆得 Old 区的,因此其回收时机是在 FullGC 时。因此,需要避免频繁的分配 DirectByteBuffer ,这样很容易导致 Native Memory 溢出。
DirectByteBuffer 申请的直接内存,不再GC范围之内,无法自动回收。JDK 提供了一种机制,可以为堆内存对象注册一个钩子函数(其实就是实现 Runnable 接口的子类),当堆内存对象被GC回收的时候,会回调run方法,我们可以在这个方法中执行释放 DirectByteBuffer 引用的直接内存,即在run方法中调用 Unsafe 的 freeMemory 方法。注册是通过sun.misc.Cleaner 类来实现的。
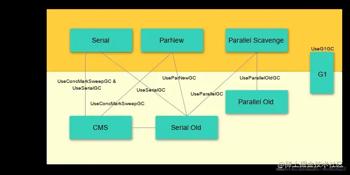
垃圾收集器是内存回收的具体实现,下图展示了 7 种用于不同分代的收集器,两个收集器之间有连线表示可以搭配使用,每种收集器都有最适合的使用场景。
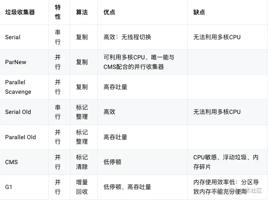
Serial 收集器是最基本的收集器,这是一个单线程收集器,它只用一个线程去完成垃圾收集工作。
虽然 Serial 收集器的缺点很明显,但是它仍然是 JVM 在 Client 模式下的默认新生代收集器。它有着优于其他收集器的地方:简单而高效(与其他收集器的单线程比较),Serial 收集器由于没有线程交互的开销,专心只做垃圾收集自然也获得最高的效率。在用户桌面场景下,分配给 JVM 的内存不会太多,停顿时间完全可以在几十到一百多毫秒之间,只要收集不频繁,这是完全可以接受的。
ParNew 是 Serial 的多线程版本,在回收算法、对象分配原则上都是一致的。ParNew 收集器是许多运行在Server 模式下的默认新生代垃圾收集器,其主要与 CMS 收集器配合工作。
Parallel Scavenge 收集器是一个新生代垃圾收集器,也是并行的多线程收集器。
Parallel Scavenge 收集器更关注可控制的吞吐量,吞吐量等于运行用户代码的时间/(运行用户代码的时间+垃圾收集时间)。
Serial Old 收集器是 Serial 收集器的老年代版本,也是一个单线程收集器,采用“标记-整理算法”进行回收。
Parallel Old 收集器是 Parallel Scavenge 收集器的老年代版本,使用多线程进行垃圾回收,其通常与 Parallel Scavenge 收集器配合使用。
CMS(Concurrent Mark Sweep)收集器是一种以获取最短停顿时间为目标的收集器, CMS 收集器采用 标记–清除 算法,运行在老年代。主要包含以下几个步骤:
其中初始标记和重新标记仍然需要 Stop the world。初始标记仅仅标记 GC Root 能直接关联的对象,并发标记就是进行 GC Root Tracing 过程,而重新标记则是为了修正并发标记期间,因用户程序继续运行而导致标记变动的那部分对象的标记记录。
由于整个过程中最耗时的并发标记和并发清除,收集线程和用户线程一起工作,所以总体上来说, CMS 收集器回收过程是与用户线程并发执行的。虽然 CMS 优点是并发收集、低停顿,很大程度上已经是一个不错的垃圾收集器,但是还是有三个显著的缺点:
正是由于在垃圾收集阶段程序还需要运行,即还需要预留足够的内存空间供用户使用,因此 CMS 收集器不能像其他收集器那样等到老年代几乎填满才进行收集,需要预留一部分空间提供并发收集时程序运作使用。要是 CMS 预留的内存空间不能满足程序的要求,这是 JVM 就会启动预备方案:临时启动 Serial Old 收集器来收集老年代,这样停顿的时间就会很长。
G1收集器与CMS相比有很大的改进:
因此 G1 收集器可以实现在基本不牺牲吞吐量的情况下完成低停顿的内存回收,这是正是由于它极力的避免全区域的回收。
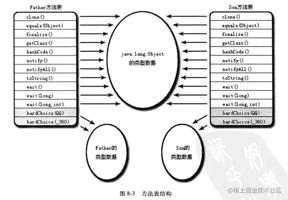
在Java中,符合“编译时可知,运行时不可变”这个要求的方法主要是静态方法和私有方法。这两种方法都不能通过继承或别的方法重写,因此它们适合在类加载时进行解析。
Java虚拟机中有四种方法调用指令:
只要能被invokestatic和invokespecial指令调用的方法,都可以在解析阶段确定唯一的调用版本,符合这个条件的有:静态方法、私有方法、实例构造器、父类方法,他们在类加载的时候就会把符号引用解析为改方法的直接引用。这些方法被称为非虚方法,反之其他方法称为虚方法(final方法除外)。
虽然final方法是使用invokevirtual 指令来调用的,但是由于它无法被覆盖,多态的选择是唯一的,所以是一种非虚方法。
对于类字段的访问也是采用静态分派
People man = new Man()
静态分派主要针对重载,方法调用时如何选择。在上面的代码中,People被称为变量的引用类型,Man被称为变量的实际类型。静态类型是在编译时可知的,而动态类型是在运行时可知的,编译器不能知道一个变量的实际类型是什么。
编译器在重载时候通过参数的静态类型而不是实际类型作为判断依据。并且静态类型在编译时是可知的,所以编译器根据重载的参数的静态类型进行方法选择。
在某些情况下有多个重载,那编译器如何选择呢? 编译器会选择”最合适”的函数版本,那么怎么判断”最合适“呢?越接近传入参数的类型,越容易被调用。
动态分派主要针对重写,使用invokevirtual指令调用。invokevirtual指令多态查找过程:
由于动态分派是非常繁琐的动作,而且动态分派的方法版本选择需要考虑运行时在类的方法元数据中搜索合适的目标方法,因此在虚拟机的实现中基于性能的考虑,在方法区中建立一个虚方法表(invokeinterface 有接口方法表),来提高性能。
在 JAVA 语言中有 8 中基本类型和一种比较特殊的类型 String 。这些类型为了使他们在运行过程中速度更快,更节省内存,都提供了一种常量池的概念。常量池就类似一个 JAVA 系统级别提供的缓存。
String 类型的常量池比较特殊。它的主要使用方法有两种:
/**
* Returns a canonical representation for the string object.
* <p>
* A pool of strings, initially empty, is maintained privately by the
* class {@code String}.
* <p>
* When the intern method is invoked, if the pool already contains a
* string equal to this {@code String} object as determined by
* the {@link #equals(Object)} method, then the string from the pool is
* returned. Otherwise, this {@code String} object is added to the
* pool and a reference to this {@code String} object is returned.
* <p>
* It follows that for any two strings {@code s} and {@code t},
* {@code s.intern() == t.intern()} is {@code true}
* if and only if {@code s.equals(t)} is {@code true}.
* <p>
* All literal strings and string-valued constant expressions are
* interned. String literals are defined in section 3.10.5 of the
* <cite>The Java™ Language Specification</cite>.
*
* @return a string that has the same contents as this string, but is
* guaranteed to be from a pool of unique strings.
*/
public native String intern();
JAVA 使用 jni 调用 c++ 实现的 StringTable 的 intern 方法, StringTable 跟 Java 中的 HashMap 的实现是差不多的, 只是 不能自动扩容。默认大小是 1009 。
要注意的是, String 的 String Pool 是一个固定大小的 Hashtable ,默认值大小长度是 1009 ,如果放进 String Pool 的 String 非常多,就会造成 Hash 冲突严重,从而导致链表会很长,而链表长了后直接会造成的影响就是当调用 String.intern 时性能会大幅下降。
在 JDK6 中 StringTable 是固定的,就是 1009 的长度,所以如果常量池中的字符串过多就会导致效率下降很快。在 jdk7 中, StringTable 的长度可以通过一个参数指定:
-XX:StringTableSize=99991
在 JDK6 以及以前的版本中,字符串的常量池是放在堆的 Perm 区。在 JDK7 的版本中,字符串常量池已经从 Perm 区移到正常的 Java Heap 区域
public static void main(String[] args) {
String s = new String("1");
s.intern();
String s2 = "1";
System.out.println(s == s2);
String s3 = new String("1") + new String("1");
s3.intern();
String s4 = "11";
System.out.println(s3 == s4);
}
上述代码的执行结果:
public static void main(String[] args) {
String s = new String("1");
String s2 = "1";
s.intern();
System.out.println(s == s2);
String s3 = new String("1") + new String("1");
String s4 = "11";
s3.intern();
System.out.println(s3 == s4);
}
上述代码的执行结果:
由于 JDK7 将字符串常量池移动到 Heap 中,导致上述版本差异,下面具体来分析下。
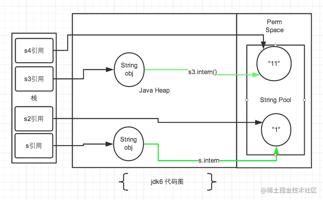
图中绿色线条代表 string 对象的内容指向,黑色线条代表地址指向
在 jdk6 中上述的所有打印都是 false ,因为 jdk6 中的常量池是放在 Perm 区中的, Perm 区和正常的 JAVA Heap 区域是完全分开的。上面说过如果是使用引号声明的字符串都是会直接在字符串常量池中生成,而 new 出来的 String 对象是放在 JAVA Heap 区域。所以拿一个 JAVA Heap 区域的对象地址和字符串常量池的对象地址进行比较肯定是不相同的,即使调用 String.intern 方法也是没有任何关系的。
因为字符串常量池移动到 JAVA Heap 区域后,再来解释为什么会有上述的打印结果。
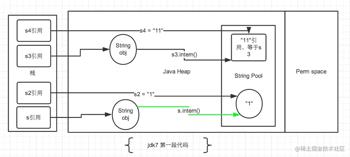
接下来是第二段代码:
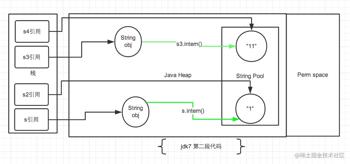
从上述的例子代码可以看出 jdk7 版本对 intern 操作和常量池都做了一定的修改。主要包括2点:
static final int MAX = 1000 * 10000;
static final String[] arr = new String[MAX];
public static void main(String[] args) throws Exception {
Integer[] DB_DATA = new Integer[10];
Random random = new Random(10 * 10000);
for (int i = 0; i < DB_DATA.length; i++) {
DB_DATA[i] = random.nextInt();
}
long t = System.currentTimeMillis();
for (int i = 0; i < MAX; i++) {
//arr[i] = new String(String.valueOf(DB_DATA[i % DB_DATA.length]));
arr[i] = new String(String.valueOf(DB_DATA[i % DB_DATA.length])).intern();
}
System.out.println((System.currentTimeMillis() - t) + "ms");
System.gc();
}
运行的参数是:-Xmx2g -Xms2g -Xmn1500M 上述代码是一个演示代码,其中有两条语句不一样,一条是使用 intern,一条是未使用 intern。
通过上述结果,我们发现不使用 intern 的代码生成了 1000w 个字符串,占用了大约 640m 空间。 使用了 intern 的代码生成了 1345 个字符串,占用总空间 133k 左右。其实通过观察程序中只是用到了 10 个字符串,所以准确计算后应该是正好相差 100w 倍。虽然例子有些极端,但确实能准确反应出 intern 使用后产生的巨大空间节省。
细心的同学会发现使用了 intern 方法后时间上有了一些增长。这是因为程序中每次都是用了 new String 后,然后又进行 intern 操作的耗时时间,这一点如果在内存空间充足的情况下确实是无法避免的,但我们平时使用时,内存空间肯定不是无限大的,不使用 intern 占用空间导致 jvm 垃圾回收的时间是要远远大于这点时间的。 毕竟这里使用了 1000w 次 intern 才多出来1秒钟多的时间。
fastjson 中对所有的 json 的 key 使用了 intern 方法,缓存到了字符串常量池中,这样每次读取的时候就会非常快,大大减少时间和空间。而且 json 的 key 通常都是不变的。这个地方没有考虑到大量的 json key 如果是变化的,那就会给字符串常量池带来很大的负担。
这个问题 fastjson 在1.1.24版本中已经将这个漏洞修复了。程序加入了一个最大的缓存大小,超过这个大小后就不会再往字符串常量池中放了。
一旦一个类被装载、连接和初始化,它就随时可以被使用。程序可以访问它的静态字段,调用它的静态方法,或者创建它的实例。作为Java程序员有必要了解Java对象的生命周期。
在Java程序中,类可以被明确或隐含地实例化。明确的实例化类有四种途径:
隐含的实例化:
Java编译器为它编译的每个类至少生成一个实例初始化方法。在Java class文件中,这个方法被称为<init>。针对源代码中每个类的构造方法,Java编译器都会产生一个<init>()方法。如果类没有明确的声明任何构造方法,编译器会默认产生一个无参数的构造方法,它仅仅调用父类的无参构造方法。
一个<init>()中可能包含三种代码:调用另一个<init>()、实现对任何实例变量的初始化、构造方法体的代码。
如果构造方法明确的调用了同一个类中的另一个构造方法(this()),那么它对应的<init>()由两部分组成:
在它对应的<init>()方法中不会有父类的<init>(),但不代表不会调用父类的<init>(),因为this()中也会调用父类<init>()
如果构造方法不是通过一个this()调用开始的,而且这个对象不是Object,<init>()则有三部分组成:
如果构造方法明确的调用父类的构造方法super()开始,它的<init>()会调用对应父类的<init>()。比如,如果一个构造方法明确的调用super(int,String)开始,对应的<init>()会从调用父类的<init>(int,String)方法开始。如果构造方法没有明确地从this()或super()开始,对应的<init>()默认会调用父类的无参<init>()。
程序可以明确或隐含的为对象分配内存,但不能明确的释放内存。一个对象不再为程序引用,虚拟机必须回收那部分内存。
在很多方面,Java虚拟机中类的生命周期和对象的生命周期很相似。当程序不再使用某个类的时候,可以选择卸载它们。
类的垃圾收集和卸载值所以在Java虚拟机中很重要,是因为Java程序可以在运行时通过用户自定义的类装载器装载类型来动态的扩展程序。所有被装载的类型都在方法区占据内存空间。
Java虚拟机通过判断类是否在被引用来进行垃圾收集。判断动态装载的类的Class实例在正常的垃圾收集过程中是否可触及有两种方式:
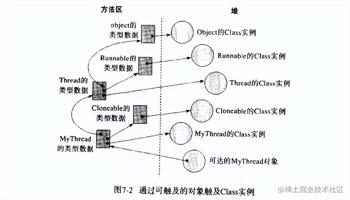
以上就是关于不用root的gg修改器_gg修改器不需要root的全部内容,游戏大佬们学会了吗?
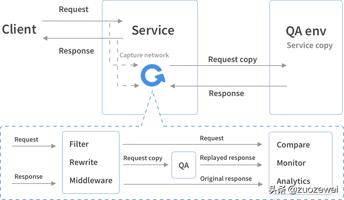
gg免root版修改器_gg免root修改器官网下载 分类:免root版 4,399人在玩 各位游戏大佬大家好,今天小编为大家分享关于gg免root版修改器_gg免root修改器官网下载的内容,轻松修改游戏数据,赶快来一起来看看吧。 一、Goreplay 介绍 Goreplay 使用 Golang……
下载
方舟gg修改器免root_方舟gg修改器免root版 分类:免root版 5,404人在玩 各位游戏大佬大家好,今天小编为大家分享关于方舟gg修改器免root_方舟gg修改器免root版的内容,轻松修改游戏数据,赶快来一起来看看吧。 8月9日,华为EMUI官方微博发了这么一条……
下载
gg修改器免root版官方_gg修改器免root版官网下载 分类:免root版 7,015人在玩 各位游戏大佬大家好,今天小编为大家分享关于gg修改器免root版官方_gg修改器免root版官网下载的内容,轻松修改游戏数据,赶快来一起来看看吧。 而在平安保险推出的“平安福”产品中……
下载
gg修改器免root版美化,下载一个神奇的软件gg修改器免root版美化 分类:免root版 4,130人在玩 如果你是一位手机玩家,那么你一定知道gg修改器。它是一款非常流行的游戏外挂,可以让你在游戏中获得无限金币、钻石和其他道具。但是今天,我要向大家介绍的不是这个功能强大的gg修……
下载
gg修改器上的root在哪下载,下载GG修改器Root版的最佳选择 分类:免root版 4,938人在玩 GG修改器是一款非常流行的游戏内存修改工具,它可以帮助玩家在游戏中获得更多资源或者跳过某些难关。与其他同类软件相比,GG修改器拥有更加丰富和强大的功能,因此备受玩家们的青睐……
下载
怎样下载gg修改器无root,如何无root下载使用gg修改器 分类:免root版 5,335人在玩 GG修改器是一款非常强大的游戏辅助工具,它可以帮助玩家在游戏中获得更多的优势。然而,很多玩家因为不会root手机而无法使用GG修改器,这让他们非常苦恼。今天我们就来介绍一种无需……
下载
王者荣耀冷却修改器,王者荣耀技能无冷却修改器下载 分类:免root版 7,426人在玩 各路英雄们好!小编接下来带来的神器是这款王者荣耀冷却修改器是一款操作灵活可修改技能冷却时机的应用,王者荣耀冷却修改器免root轻松修改,王者荣耀冷却修改器让你在游戏中可以任……
下载
gg修改器免root版2_gg修改器免root版2020年最新版本 分类:免root版 7,059人在玩 各位游戏大佬大家好,今天小编为大家分享关于gg修改器免root版2_gg修改器免root版2020年最新版本的内容,轻松修改游戏数据,赶快来一起来看看吧。 各位小哥哥小姐姐下午好,又到了……
下载
小米gg修改器没root,小米GG修改器无需ROOT,下载使用更加方便 分类:免root版 4,128人在玩 作为一名游戏爱好者,在游戏中获得胜利是最重要的事情之一。而有时候,我们需要一些外部帮助来实现这一目标。小米GG修改器就是这样一个优秀的游戏辅助工具,它能够在不需要ROOT的情……
下载
怎么让gg修改器免root,让GG修改器免Root,这个软件就是你需要的! 分类:免root版 3,299人在玩 如果您想要在玩游戏时获得更多的优势,那么使用GG修改器可能是一个不错的选择。但是,很多人都会遇到一个问题:GG修改器需要Root权限。对于不熟悉技术操作的用户来说,这可能是一个……
下载