
各位游戏大佬大家好,今天小编为大家分享关于滑稽gg修改器免root_滑稽版gg修改器的内容,轻松修改游戏数据,赶快来一起来看看吧。
选自 Medium,作者:Adam Geitgey,机器之心编译,参与:Nurhachu Null、Chita。
作者想用深度学习来解决一个小麻烦,于是用 Python 和 Mask R-CNN 设计了一个模型。该模型可以自动检测停车位并在发现可用车位后向他发送短信。这是什么神仙(sao)操作?

机器学习流程的输入是来自一个伸出窗外的普通网络摄像头的视频流:

我们需要扫描这幅图,然后返回一个有效停车区域列表,就像这样:

这个城市街道上的有效停车位。
一种比较懒的方法就是手动把每个停车位的位置硬编码到程序中,而不是自动检测停车位。但是如果我们移动了摄像头或者想要检测另一条街道上的车位时,就必须再一次手动硬编码车位的位置。这样很麻烦,还是找一种自动检测车位的方法吧。
一个思路是寻找停车计时器并假设每个计时器旁边都有一个停车位:

检测每幅图像中的停车计时器。
但这种方法有些复杂。首先,并非每个停车位都有停车计时器——实际上,我们最喜欢找的是无需付费的车位!其次,只知道停车计时器的位置并不能确切地告诉我们停车位的确切位置。它只是让我们更加接近停车位罢了。
另一个思路就是构建目标检测模型,让它寻找道路上绘制的停车位标志,就像这样:

请注意这些黄色的小标志——它们就是画在道路上的每个车位的边界。
但是这种方法也很令人痛苦。首先,我所在城市的停车位标志线特别小,在这么远的距离很难看见,所以很难用计算机检测到它们。其次,道路上有各种无关的线和标志。很难区分哪些线是停车位标志,哪些是车道分离线或者人行道线。
当你遇到似乎很困难的问题时,花几分钟时间想一想,你是否可以采用不同的方法来解决这个问题,避开一些技术性挑战。到底什么是停车位?停车位不就是车辆可以停放很长时间的地方吗。所以,也许我们根本就没必要去检测停车位。为何不能仅仅检测长时间没有移动的车辆并且假设它们就停在停车位呢?
换句话说,有效停车位就是包含非移动车辆的地方。

这里,每辆车的边界框实际上就是一个停车位!如果我们能够检测静态的车辆,就没必要检测停车位。
所以,如果我们能够检测车辆,并且可以判断哪些车辆在视频帧中是没有移动的,那我们就能够推测出停车位的位置。够简单了——让我们来检测车辆吧!
检测视频帧里的车辆就是目标检测中的一道练习题。我们可以用很多机器学习方法来检测图像中的目标。下面是我列出的几种最常用的目标检测算法:
通常情况下,我们希望选择最简单的方法来解决问题,使用最少的训练数据,并不认为需要最新、最流行的算法。但是在这个特殊的情况下,*Mask R-CNN*是一个比较合理的选择,虽然它是一个比较新、比较流行的算法。
Mask R-CNN 架构在不使用滑动窗口的情况下以一种高效的计算方式在整幅图像中检测目标。换句话说,它运行得相当快。在具有比较先进的 GPU 时,我们应该能够以数帧每秒的速度检测到高分辨率视频中的目标。所以它应该比较适合这个项目。
此外,Mask R-CNN 给我们提供了很多关于每个检测对象的信息。绝大多数目标检测算法仅仅返回了每个对象的边界框。但是 Mask R-CNN 并不会仅仅给我们提供每个对象的位置,它还会给出每个对象的轮廓 (掩模),就像这样:

为了训练 Mask R-CNN,我们需要大量关于需要检测的目标的图像。我们可以拍一些车辆的图像,然后将这些图像中的汽车标注出来,但是这可能会花费几天的工作。幸运的是,汽车是很常见的检测目标,很多人都想检测,因此早就有了几个公开的汽车数据集。
有一个很流行的数据集叫做 COCO,它里面的图像都用目标掩膜标注过。在这个数据集中,已经有超过 12000 张汽车图像做好了轮廓标注。下面就是 COCO 数据集中的一张图像。

COCO 数据集中已标注轮廓的图像。
这个数据集非常适合用来训练 Mask R-CNN 模型。
使用 COCO 数据集来构建目标检测数据集是很常见的一件事情,所以好多人已经做过并且分享了他们的结果。因此,我们可以用一个训练好的模型作为开始,而不用从头去训练自己的模型。针对这个项目,我们可以使用很棒的开源 Mask R-CNN,它是由 Matterport 公司实现的,还提供了训练好的模型。
地址:https:///matterport/Mask_RCNN
旁注:你不必为训练定制化的 Mask R-CNN 而担心!标注数据是很耗时间的,但是并不困难。如果你想使用自己的数据完整地训练 Mask R-CNN 模型,可以参考这本书:
https://www./get-the-book
如果在我自己的相机图像上运行预训练模型,以下是检测结果:
经过 COCO 默认目标识别的图像——车辆、人、交通信号灯和树。
我们不仅识别了车辆,还识别出了交通信号灯和人。而且比较滑稽的是,它将其中的一棵树识别成了「盆栽植物」。
对于图像中被检测到的每一个目标,我们从 Mask R-CNN 模型中得到了下面四个结果:
下面是 python 代码,用于根据 Matterport』s Mask R-CNN 实现和 OpneCV 预训练的模型来检测汽车边界框:
import os
import numpy as np
import cv2
import n.config
import n.utils
from n.model import MaskRCNN
from pathlib import Path
# Configuration that will be used by the Mask-RCNN library
class MaskRCNNConfig(n.config.Config):
NAME = “coco_pretrained_model_config”
IMAGES_PER_GPU = 1
GPU_COUNT = 1
NUM_CLASSES = 1 + 80 # COCO dataset has 80 classes + one background class
DETECTION_MIN_CONFIDENCE = 0.6
# Filter a list of Mask R-CNN detection results to get only the detected cars / trucks
def get_car_boxes(boxes, class_ids):
car_boxes = []
for i, box in enumerate(boxes):
# If the detected object isn’t a car / truck, skip it
if class_ids[i] in [3, 8, 6]:
car_boxes.append(box)
return np.array(car_boxes)
# Root directory of the project
ROOT_DIR = Path(“.”)
# Directory to save logs and trained model
MODEL_DIR = os.path.join(ROOT_DIR, “logs”)
# Local path to trained weights file
COCO_MODEL_PATH = os.path.join(ROOT_DIR, “mask_rcnn_coco.h5”)
# Download COCO trained weights from Releases if needed
if not os.path.exists(COCO_MODEL_PATH):
n.utils.download_trained_weights(COCO_MODEL_PATH)
# Directory of images to run detection on
IMAGE_DIR = os.path.join(ROOT_DIR, “images”)
# Video file or camera to process – set this to 0 to use your webcam instead of a video file
VIDEO_SOURCE = “test_images/parking.mp4″
# Create a Mask-RCNN model in inference mode
model = MaskRCNN(mode=”inference”, model_dir=MODEL_DIR, config=MaskRCNNConfig())
# Load pre-trained model
model.load_weights(COCO_MODEL_PATH, by_name=True)
# Location of parking spaces
parked_car_boxes = None
# Load the video file we want to run detection on
video_capture = cv2.VideoCapture(VIDEO_SOURCE)
# Loop over each frame of video
while video_capture.isOpened():
success, frame = video_capture.read()
if not success:
break
# Convert the image from BGR color (which OpenCV uses) to RGB color
rgb_image = frame[:, :, ::-1]
# Run the image through the Mask R-CNN model to get results.
results = model.detect([rgb_image], verbose=0)
# Mask R-CNN assumes we are running detection on multiple images.
# We only passed in one image to detect, so only grab the first result.
r = results[0]
# The r variable will now have the results of detection:
# – r[’rois’] are the bounding box of each detected object
# – r[’class_ids’] are the class id (type) of each detected object
# – r[’scores’] are the confidence scores for each detection
# – r[’masks’] are the object masks for each detected object (which gives you the object outline)
# Filter the results to only grab the car / truck bounding boxes
car_boxes = get_car_boxes(r[’rois’], r[’class_ids’])
print(“Cars found in frame of video:”)
# Draw each box on the frame
for box in car_boxes:
print(“Car: “, box)
y1, x1, y2, x2 = box
# Draw the box
cv2.rectangle(frame, (x1, y1), (x2, y2), (0, 255, 0), 1)
# Show the frame of video on the screen
cv2.imshow(’Video’, frame)
# Hit ’q’ to quit
if cv2.waitKey(1) & 0xFF == ord(’q’):
break
# Clean up everything when finished
video_capture.release()
cv2.destroyAllWindows()
当你运行这段脚本时,会在屏幕上得到一幅图,每辆检测到的汽车都有一个边界框,像这样:

每辆检测到的汽车都有一个绿色的边界框。
你还会看到被检测到的汽车坐标被打印在了控制台上,就像这样:
Cars found in frame of video:
Car: [492 871 551 961]
Car: [450 819 509 913]
Car: [411 774 470 856]
经过以上这些步骤,我们已经成功地检测到了图像中的汽车。
检测空置的停车位
我们知道了每张图像中每辆车的像素位置。通过查看视频中按顺序出现的多帧,我们可以轻易知道哪些车没有动,并且假设它们所在的位置就是车位。但是,当一辆车离开车位的时候,我们如何检测得到呢?
问题在于我们图像中的边界框是部分重叠的。
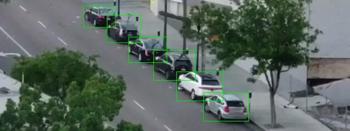
即使是在不同车位中的车辆,每辆车的边界框都会有一小部分的重叠。
所以,如果我们假设每个边界框代表一个车位,那么,即使车位是空的,也有可能显示为被部分占用。我们需要一个方法来测量两个对象的重叠度,以便检查「大部分是空的」边界框。
我们将要使用的测量方法为交并比(IoU)。IoU 通过两个对象重叠的像素数量除以两个对象覆盖的像素数量计算得到。像这样:
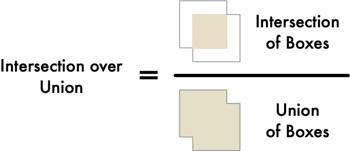
这将为我们提供汽车边界框与停车位边界框重叠的程度。有了这个,我们可以轻易确定汽车是否在停车位。如果 IoU 测量值很低,如 0.15,那意味着汽车并没有真正占用大部分停车位。但如果指标很高,如 0.6,这意味着汽车占据了大部分停车位区域,因此我们可以确定该空间被占用。
由于 IoU 是计算机视觉中常见的测量方法,因此你在使用的库通常已经实现了它的计算。事实上,Matterport Mask R-CNN 库将它作为一个名为 n.pute_overlaps()的函数包含在内,因此我们可以直接使用该函数。
假设我们有一个表示图像中停车区域的边界框列表,查看检测到的车辆是否在这些边界框内就像添加一行或两行代码一样简单:
# Filter the results to only grab the car / truck bounding boxes
car_boxes = get_car_boxes(r[’rois’], r[’class_ids’])
# See how much cars overlap with the known parking spaces
overlaps = n.pute_overlaps(car_boxes, parking_areas)
print(overlaps)
结果是这样子的:
[
[1. 0.07040032 0. 0.]
[0.07040032 1. 0.07673165 0.]
[0. 0. 0.02332112 0.]
]
In that 2D array, each
在这个二维数组中,每一行代表一个停车位的边界框。同样,每一列代表着这个停车位被检测到的汽车占用了多少。1.0 分表示完全被占用,较低的分,如 0.02 则表示这辆汽车接触到了车位的空间,但是并没有占据大部分区域。
要寻找未被占用的停车位,我们只需要检查此阵列中的每一行。如果所有数字都为零或非常小,那意味着没有任何东西占据那个空间,它就是空着的!
但请记住,目标检测并非总是与实时视频完美配合。即使 Mask R-CNN 非常准确,偶尔也会在单帧视频中错过一两辆车。因此,在将停车位标记为空闲之前,我们应该确保它在一段时间内保持空闲 – 可能是 5 或 10 个连续的视频帧。这将防止系统仅仅因为目标检测在一帧视频上有短暂的停顿就错误地检测到空闲的停车位。但是,只要我们看到至少有一个空闲停车位出现在连续几帧视频中,我们就可以发送短信了!
这个项目的最后一步就是当检测到一个空闲停车位出现在视频的连续几帧中时就发送短信提醒。
使用 Twilio 从 Python 中发送短信很简单。Twilio 是一个很流行的 API,它可以让你用任何编程语言只需几行代码就可以发送短信。当然,如果你更喜欢使用其它短信服务提供商,也可以。我和 Twilio 并没有利益关系。它只是我想到的第一个工具而已。
要使用 Twilio,你需要注册一个试用账户,创建两个 Twilio 电话号码,然后认证账户。然后,你需要安装 Twilio Python 客户端。
pip3 install twilio
安装完成后,这是用 Python 发送短信的完整代码(只需用你自己的帐户详细信息替换这些值即可):
from twilio.rest import Client
# Twilio account details
twilio_account_sid = ’Your Twilio SID here’
twilio_auth_token = ’Your Twilio Auth Token here’
twilio_source_phone_number = ’Your Twilio phone number here’
# Create a Twilio client object instance
client = Client(twilio_account_sid, twilio_auth_token)
# Send an SMS
message = client.messages.create(
body=”This is my SMS message!”,
from_=twilio_source_phone_number,
to=”Destination phone number here”
)
为了在脚本中添加短信发送功能,我们可以把这些代码丢进去。但需要注意的是,我们并不需要在每一个有空闲车位的新视频帧中发送短信。所以我们需要一个标志来跟踪是否已经发过短信了,这是为了保证不会在短期内再次发送或者在新车位空出来之前再次发送。
将以上流程中的所有步骤整合在一起,构成一个独立的 Python 脚本,完整代码如下所示:
import os
import numpy as np
import cv2
import n.config
import n.utils
from n.model import MaskRCNN
from pathlib import Path
from twilio.rest import Client
# Configuration that will be used by the Mask-RCNN library
class MaskRCNNConfig(n.config.Config):
NAME = “coco_pretrained_model_config”
IMAGES_PER_GPU = 1
GPU_COUNT = 1
NUM_CLASSES = 1 + 80 # COCO dataset has 80 classes + one background class
DETECTION_MIN_CONFIDENCE = 0.6
# Filter a list of Mask R-CNN detection results to get only the detected cars / trucks
def get_car_boxes(boxes, class_ids):
car_boxes = []
for i, box in enumerate(boxes):
# If the detected object isn’t a car / truck, skip it
if class_ids[i] in [3, 8, 6]:
car_boxes.append(box)
return np.array(car_boxes)
# Twilio config
twilio_account_sid = ’YOUR_TWILIO_SID’
twilio_auth_token = ’YOUR_TWILIO_AUTH_TOKEN’
twilio_phone_number = ’YOUR_TWILIO_SOURCE_PHONE_NUMBER’
destination_phone_number = ’THE_PHONE_NUMBER_TO_TEXT’
client = Client(twilio_account_sid, twilio_auth_token)
# Root directory of the project
ROOT_DIR = Path(“.”)
# Directory to save logs and trained model
MODEL_DIR = os.path.join(ROOT_DIR, “logs”)
# Local path to trained weights file
COCO_MODEL_PATH = os.path.join(ROOT_DIR, “mask_rcnn_coco.h5”)
# Download COCO trained weights from Releases if needed
if not os.path.exists(COCO_MODEL_PATH):
n.utils.download_trained_weights(COCO_MODEL_PATH)
# Directory of images to run detection on
IMAGE_DIR = os.path.join(ROOT_DIR, “images”)
# Video file or camera to process – set this to 0 to use your webcam instead of a video file
VIDEO_SOURCE = “test_images/parking.mp4″
# Create a Mask-RCNN model in inference mode
model = MaskRCNN(mode=”inference”, model_dir=MODEL_DIR, config=MaskRCNNConfig())
# Load pre-trained model
model.load_weights(COCO_MODEL_PATH, by_name=True)
# Location of parking spaces
parked_car_boxes = None
# Load the video file we want to run detection on
video_capture = cv2.VideoCapture(VIDEO_SOURCE)
# How many frames of video we’ve seen in a row with a parking space open
free_space_frames = 0
# Have we sent an SMS alert yet?
sms_sent = False
# Loop over each frame of video
while video_capture.isOpened():
success, frame = video_capture.read()
if not success:
break
# Convert the image from BGR color (which OpenCV uses) to RGB color
rgb_image = frame[:, :, ::-1]
# Run the image through the Mask R-CNN model to get results.
results = model.detect([rgb_image], verbose=0)
# Mask R-CNN assumes we are running detection on multiple images.
# We only passed in one image to detect, so only grab the first result.
r = results[0]
# The r variable will now have the results of detection:
# – r[’rois’] are the bounding box of each detected object
# – r[’class_ids’] are the class id (type) of each detected object
# – r[’scores’] are the confidence scores for each detection
# – r[’masks’] are the object masks for each detected object (which gives you the object outline)
if parked_car_boxes is None:
# This is the first frame of video – assume all the cars detected are in parking spaces.
# Save the location of each car as a parking space box and go to the next frame of video.
parked_car_boxes = get_car_boxes(r[’rois’], r[’class_ids’])
else:
# We already know where the parking spaces are. Check if any are currently unoccupied.
# Get where cars are currently located in the frame
car_boxes = get_car_boxes(r[’rois’], r[’class_ids’])
# See how much those cars overlap with the known parking spaces
overlaps = n.pute_overlaps(parked_car_boxes, car_boxes)
# Assume no spaces are free until we find one that is free
free_space = False
# Loop through each known parking space box
for parking_area, overlap_areas in zip(parked_car_boxes, overlaps):
# For this parking space, find the max amount it was covered by any
# car that was detected in our image (doesn’t really matter which car)
max_IoU_overlap = np.max(overlap_areas)
# Get the top-left and bottom-right coordinates of the parking area
y1, x1, y2, x2 = parking_area
# Check if the parking space is occupied by seeing if any car overlaps
# it by more than 0.15 using IoU
if max_IoU_overlap < 0.15:
# Parking space not occupied! Draw a green box around it
cv2.rectangle(frame, (x1, y1), (x2, y2), (0, 255, 0), 3)
# Flag that we have seen at least one open space
free_space = True
else:
# Parking space is still occupied – draw a red box around it
cv2.rectangle(frame, (x1, y1), (x2, y2), (0, 0, 255), 1)
# Write the IoU measurement inside the box
font = cv2.FONT_HERSHEY_DUPLEX
cv2.putText(frame, f”{max_IoU_overlap:0.2}”, (x1 + 6, y2 – 6), font, 0.3, (255, 255, 255))
# If at least one space was free, start counting frames
# This is so we don’t alert based on one frame of a spot being open.
# This helps prevent the script triggered on one bad detection.
if free_space:
free_space_frames += 1
else:
# If no spots are free, reset the count
free_space_frames = 0
# If a space has been free for several frames, we are pretty sure it is really free!
if free_space_frames > 10:
# Write SPACE AVAILABLE!! at the top of the screen
font = cv2.FONT_HERSHEY_DUPLEX
cv2.putText(frame, f”SPACE AVAILABLE!”, (10, 150), font, 3.0, (0, 255, 0), 2, cv2.FILLED)
# If we haven’t sent an SMS yet, sent it!
if not sms_sent:
print(“SENDING SMS!!!”)
message = client.messages.create(
body=”Parking space open – go go go!”,
from_=twilio_phone_number,
to=destination_phone_number
)
sms_sent = True
# Show the frame of video on the screen
cv2.imshow(’Video’, frame)
# Hit ’q’ to quit
if cv2.waitKey(1) & 0xFF == ord(’q’):
break
# Clean up everything when finished
video_capture.release()
cv2.destroyAllWindows()
要运行这份代码,你首先需要安装 python 3.6+,Matterport Mask R-CNN 以及 OpenCV。
我特意保留了比较简单的代码。例如,它只是假设第一帧视频中出现的任何车辆都是停放的汽车。试用一下,看看你是否能够提升它的可用性。
不必担心为了在其它场景中使用而修改代码。仅仅改变模型寻找的目标 ID,你就能够将这份代码完全转换成另一个东西。例如,假设你在滑雪场工作。经过一些调整,你就可以将这份脚本转换为一个系统,它可以自动检测滑雪板从斜坡上跳越,并创建出很酷的滑雪板跳越路线。或者如果你在野生动物保护区工作,你可以将这份代码转换成一个统计野生斑马数量的系统。唯一的限制只是你的想象力。祝你玩得开心!
以上就是关于滑稽gg修改器免root_滑稽版gg修改器的全部内容,游戏大佬们学会了吗?

怎么免root开gg修改器_GG修改器怎样免root 分类:免root版 6,559人在玩 各位游戏大佬大家好,今天小编为大家分享关于怎么免root开gg修改器_GG修改器怎样免root的内容,轻松修改游戏数据,赶快来一起来看看吧。 如果遗忘 iOS 设备的 Apple ID 密码,在重……
下载
苹果GG修改器免root版,下载免费的苹果GG修改器免root版 分类:免root版 3,885人在玩 苹果手机是目前市场上最受欢迎的手机之一,但如果你想要更多的自由和控制权,以便定制化你的手机,那么你可能需要使用一些辅助工具。其中一个最流行的工具就是苹果GG修改器免root版……
下载
gg修改器不root能用么,软件下载:gg修改器不root版 分类:免root版 3,981人在玩 GG修改器是一款非常实用的手机辅助工具,用于在游戏中修改游戏数据。但是,传统的GG修改器需要手机root后才能使用。这对于许多人来说是一个很大的问题,因为他们可能不想或者不知道……
下载
gg修改器方舟无root_方舟GG修改器使用教程 分类:免root版 4,743人在玩 各位游戏大佬大家好,今天小编为大家分享关于gg修改器方舟无root_方舟GG修改器使用教程的内容,轻松修改游戏数据,赶快来一起来看看吧。 想体验方舟编译器的神奇吗?想体验用方舟编……
下载
GG免root框架修改器,下载GG免root框架修改器,轻松修改游戏数据 分类:免root版 2,670人在玩 如果你是一个喜欢玩手机游戏的玩家,那么你一定知道很多游戏都需要ROOT权限才能进行修改。但是,对于大多数人来说,ROOT手机并不是一件容易的事情。因此,GG免root框架修改器就应运……
下载
gg修改器手机没root,下载一个不需要root的gg修改器手机软件 分类:免root版 4,736人在玩 如果您是一名安卓手机用户,那么您可能会有想要修改游戏数据的需求。对于这样的需求,我们通常会想到使用gg修改器来达成目的。然而,许多gg修改器都需要root权限才能正常使用,而这……
下载
用gg修改器必须root吗,软件下载:GG修改器一键ROOT,免费畅享游戏体验 分类:免root版 3,564人在玩 如果你是一位游戏爱好者,那么你一定知道GG修改器这款软件。它是一款专业的游戏辅助工具,可以帮助玩家轻松实现各种游戏修改操作。目前,GG修改器已经成为了广大游戏玩家必备的软件……
下载
免root权限的gg修改器,免root权限的gg修改器为你带来全新的游戏体验 分类:免root版 2,506人在玩 如果你是一位游戏爱好者,那么你一定会知道GG修改器这个神奇的工具。它可以让你在游戏中获得无限金币、钻石和其他资源,让你轻松愉快地玩游戏。但是传统的GG修改器需要Root权限,这……
下载
王者荣耀-皮肤修改器 王者荣耀刷永久皮肤大师下载 分类:免root版 7,418人在玩 王者荣耀-皮肤修改器是一个刷永久皮肤大师工具,对于王者荣耀的玩家来说,随便哪样好的东西都是花钱的,就连皮肤虽然说是可以通过金币点券购买,到头来金币和点券实际上也就是钱……
下载
gg修改器方舟手游root,下载软件标题:轻松Root方舟手游,畅玩无忧! 分类:免root版 2,229人在玩 如果你是一位玩家,那么你一定听说过方舟手游。这款游戏因其精美的画面和独特的玩法深受广大玩家的喜爱。但是在游戏中却存在着很多的限制,比如需要耗费大量的时间去集齐资源,或者……
下载