
各位游戏大佬大家好,今天小编为大家分享关于没root怎么装GG修改器_没root怎么用gg修改器的内容,轻松修改游戏数据,赶快来一起来看看吧。
在进行CDH集群安装部署的时候,官方提供了三种方式,parcels、packages以及tarball,官方推荐使用parcels的方式进行安装,这也是最常用的安装方式,通常我们使用CM图形化界面的操作方式来安装CDH集群,本文档将介绍的是官方提供的另一种安装方式,使用packages安装,即rpm包的方式进行CDH集群的安装,并且本次安装是使用没有CM的方式进行安装。
环境介绍:
·安装部署使用root用户进行操作
·安装的CDH版本为5.10.0
·服务器的操作系统为RedHat7.2
·安装不使用CM
·CDH集群安装在三个节点
安装CDH集群时需要做一些前置的准备,本次安装使用的环境已经做好前置准备,需要做的准备如下:
1.hosts以及hostname配置正确
2.服务器没有启用IPv6且配置了静态IP
3.禁用SELinux
4.关闭防火墙
5.设置swappiness为1
6.关闭透明大页面
7.配置NTP时钟同步
1.在官网下载好需要的rpm包,地址如下:
http://archive./cdh5/redhat/7/x86_64/cdh/5.10.0/RPMS/

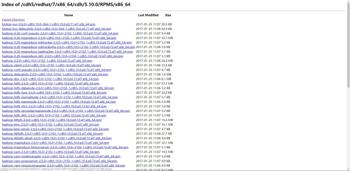
将上面所有的rpm包下载到服务器,如下:
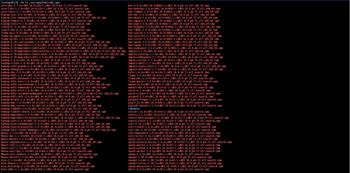
在浏览器进行验证
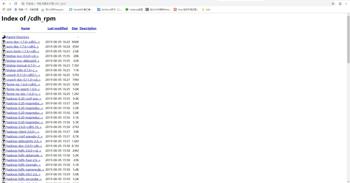
2.执行createrepo命令
createrepo .

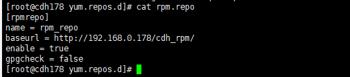
3.创建repo文件
[rpmrepo]
name = rpm_repo
baseurl = http://192.168.0.178/cdh_rpm/
enable = true
gpgcheck = false
4.执行yum命令,查看本地yum源是否配置成功
yum clean all
yum repolist
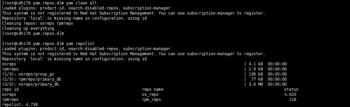
上图可以看到,下载的rpm包制作的本地yum源成功
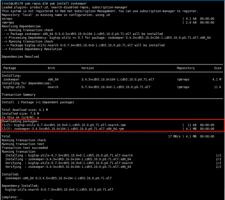
1.在所有节点安装Zookeeper
yum install zookeepe
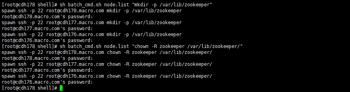
2.创建数据目录并修改属主
mkdir -p /var/lib/zookeeper
chown -R zookeeper /var/lib/zookeeper
3.修改配置文件/etc/zookeeper/conf/zoo.cfg
maxClientCnxns=60
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/var/lib/zookeeper
clientPort=2181
dataLogDir=/var/lib/zookeeper
minSessionTimeout=4000
maxSessionTimeout=40000
server.1=cdh178.:3181:4181
server.2=cdh177.:3181:4181
server.3=cdh176.:3181:4181

保存修改并同步到所有节点

4.所有节点创建myid文件并修改属主
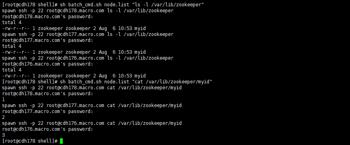
5.所有节点启动Zookeeper
/usr/lib/zookeeper/bin/zkServer.sh start

查看所有节点启动状态,三个节点均启动成功
/usr/lib/zookeeper/bin/zkServer.sh status
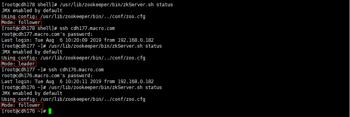
至此Zookeeper安装完成
1.在所有节点安装HDFS必需的包,由于只有三个节点,所以三个节点都安装DataNode
yum -y install hadoop hadoop-hdfs hadoop-client hadoop-doc hadoop-debuginfo hadoop-hdfs-datanode
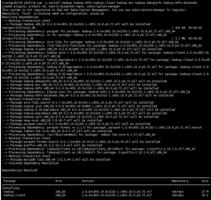
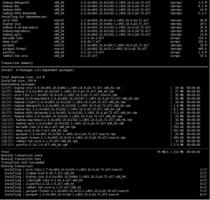
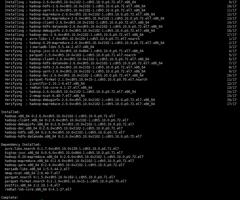
2.在一个节点安装NameNode以及SecondaryNameNode
yum -y install hadoop-hdfs-namenode hadoop-hdfs-secondarynamenode
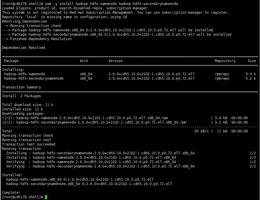
3.创建数据目录并修改属主和权限
所有节点创建DataNode的目录
mkdir -p /data0/dfs/dn
chown -R hdfs:hadoop /data0/dfs/dn
chmod 700 /data0/dfs/dn




NameNode和SecondaryNameNode节点创建数据目录
mkdir -p /data0/dfs/nn
chown -R hdfs:hadoop /data0/dfs/nn
chmod 700 /data0/dfs/nn
mkdir -p /data0/dfs/snn
chown -R hdfs:hadoop /data0/dfs/snn
chmod 700 /data0/dfs/snn

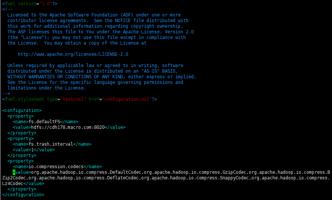
4.修改配置文件
/etc/hadoop/conf/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://cdh178.:8020</value>
</property>
<property>
<name>fs.trash.interval</name>
<value>1</value>
</property>
<property>
<name>pression.codecs</name>
<value>org.apache.hadoop.press.DefaultCodec,org.apache.hadoop.press.GzipCodec,org.apache.hadoop.press.BZip2Codec,org.apache.hadoop.press.DeflateCodec,org.apache.hadoop.press.SnappyCodec,org.apache.hadoop.press.Lz4Codec</value>
</property>
</configuration>
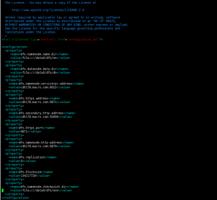
/etc/hadoop/conf/hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///data0/dfs/nn</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///data0/dfs/dn</value>
</property>
<property>
<name>dfs.namenode.servicerpc-address</name>
<value>cdh178.:8022</value>
</property>
<property>
<name>dfs.https.address</name>
<value>cdh178.:9871</value>
</property>
<property>
<name>dfs.secondary.http.address</name>
<value>cdh178.:50090</value>
</property>
<property>
<name>dfs.https.port</name>
<value>9871</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>cdh178.:9870</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.blocksize</name>
<value>134217728</value>
</property>
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>file:///data0/dfs/snn</value>
</property>
</configuration>
5.将修改的配置文件保存并同步到所有节点
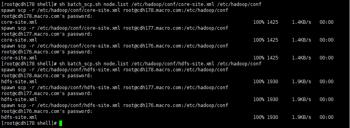
6.格式化NameNode
hdfs namenode -format

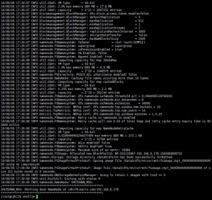
7.在所有节点运行命令启动HDFS
systemctl start hadoop-hdfs-namenode
systemctl start hadoop-hdfs-secondarynamenode
systemctl start hadoop-hdfs-datanode
systemctl status hadoop-hdfs-namenode
systemctl status hadoop-hdfs-secondarynamenode
systemctl status hadoop-hdfs-datanode
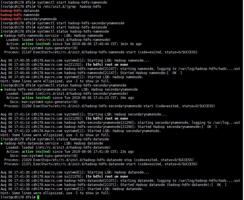
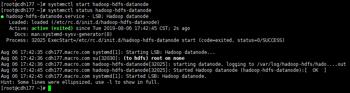
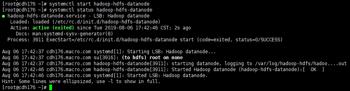
8.创建/tmp临时目录,并设置目录权限,然后使用hadoop命令查看创建的目录成功
sudo -u hdfs hadoop fs -mkdir /tmp
sudo -u hdfs hadoop fs -chmod -R 1777 /tmp

9.访问NameNode的Web UI
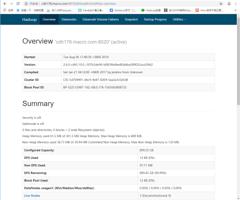
至此HDFS安装完成
1.安装Yarn的包,在一个节点安装ResourceManager和JobHistory Server,另外两个节点安装NodeManager
yum -y install hadoop-yarn hadoop-yarn-resourcemanager hadoop-mapreduce-historyserver hadoop-yarn-proxyserver hadoop-mapreduce
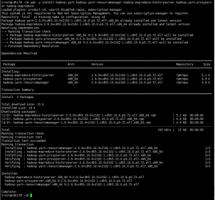
yum -y install hadoop-yarn hadoop-yarn-nodemanager hadoop-mapreduce
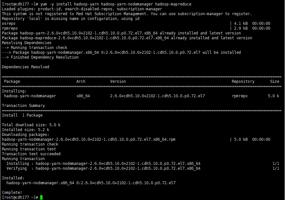
2.创建目录并修改属主和权限
在所有节点创建本地目录
mkdir -p /data0/yarn/nm
chown yarn:hadoop /data0/yarn/nm
mkdir -p /data0/yarn/container-logs
chown yarn:hadoop /data0/yarn/container-logs
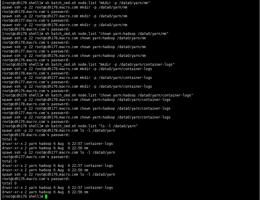
在HDFS上创建logs目录
sudo -u hdfs hdfs dfs -mkdir /tmp/logs
sudo -u hdfs hdfs dfs -chown mapred:hadoop /tmp/logs
sudo -u hdfs hdfs dfs -chmod 1777 /tmp/logs

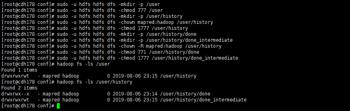
在HDFS上创建/user/history目录
sudo -u hdfs hdfs dfs -mkdir -p /user
sudo -u hdfs hdfs dfs -chmod 777 /user
sudo -u hdfs hdfs dfs -mkdir -p /user/history
sudo -u hdfs hdfs dfs -chown mapred:hadoop /user/history
sudo -u hdfs hdfs dfs -chmod 1777 /user/history
sudo -u hdfs hdfs dfs -mkdir -p /user/history/done
sudo -u hdfs hdfs dfs -mkdir -p /user/history/done_intermediate
sudo -u hdfs hdfs dfs -chown -R mapred:hadoop /user/history
sudo -u hdfs hdfs dfs -chmod 771 /user/history/done
sudo -u hdfs hdfs dfs -chmod 1777 /user/history/done_intermediate
3.修改配置文件
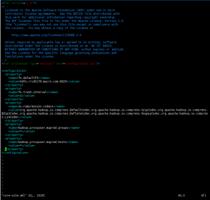
/etc/hadoop/conf/yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>file:///data0/yarn/nm</value>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>file:///data0/yarn/container-logs</value>
</property>
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/tmp/logs</value>
</property>
<property>
<name>yarn.application.classpath</name>
<value>$HADOOP_CONF_DIR,$HADOOP_COMMON_HOME/*,$HADOOP_COMMON_HOME/lib/*,$HADOOP_HDFS_HOME/*,$HADOOP_HDFS_HOME/lib/*,$HADOOP_MAPRED_HOME/*,$HADOOP_MAPRED_HOME/lib/*,$HADOOP_YARN_HOME/*,$HADOOP_YARN_HOME/lib/*</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>cdh178.:8032</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>cdh178.:8033</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>cdh178.:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>cdh178.:8031</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>cdh178.:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.https.address</name>
<value>cdh178.:8090</value>
</property>
</configuration>
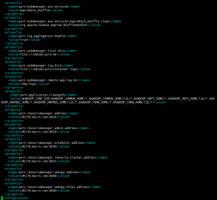
/etc/hadoop/conf/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>cdh178.:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>cdh178.:19888</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.https.address</name>
<value>cdh178.:19890</value>
</property>
<property>
<name>mapreduce.jobhistory.admin.address</name>
<value>cdh178.:10033</value>
</property>
<property>
<name>yarn.app.mapreduce.am.staging-dir</name>
<value>/user</value>
</property>
</configuration>
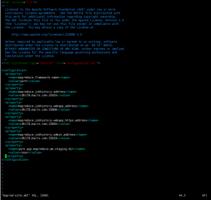
/etc/hadoop/conf/core-site.xml,下面只贴出修改的部分配置
<property>
<name>hadoop.proxyuser.mapred.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.mapred.hosts</name>
<value>*</value>
</property>
4.将配置文件保存后同步到所有节点
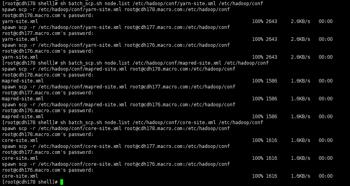
5.启动Yarn服务
在JobHistoryServer节点上启动mapred-historyserver
/etc/init.d/hadoop-mapreduce-historyserver start
在RM节点启动ResourceManager
systemctl start hadoop-yarn-resourcemanager
systemctl status hadoop-yarn-resourcemanager
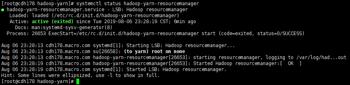
在NM节点启动NodeManager
systemctl start hadoop-yarn-nodemanager
systemctl status hadoop-yarn-nodemanager
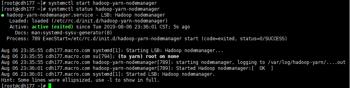
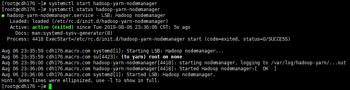
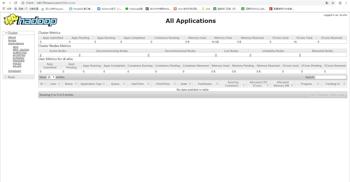
6.访问Yarn服务的Web UI
Yarn的管理页面
JobHistory的管理页面
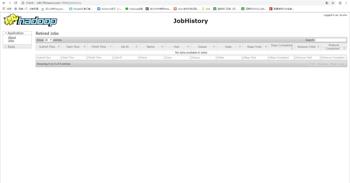
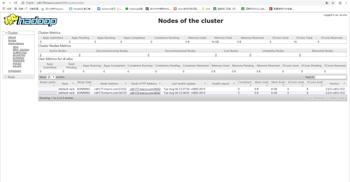
查看在线的节点
7.运行MR示例程序
使用root用户运行示例程序,所以要先创建root用户的目录
sudo -u hdfs hdfs dfs -mkdir /user/root
sudo -u hdfs hdfs dfs -chown root:root /user/root

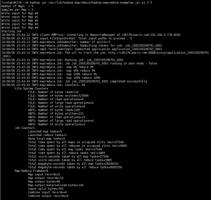
运行MR示例程序,运行成功
hadoop jar /usr/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar pi 5 5
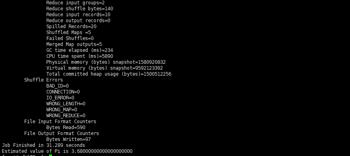
至此Yarn服务安装完成
1.安装Spark所需的包
yum install spark-core spark-master spark-worker spark-history-server spark-python
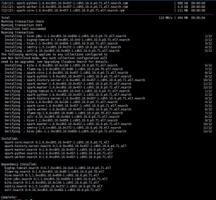
2.创建目录并修改属主和权限
sudo -u hdfs hadoop fs -mkdir /user/spark
sudo -u hdfs hadoop fs -mkdir /user/spark/applicationHistory
sudo -u hdfs hadoop fs -chown -R spark:spark /user/spark
sudo -u hdfs hadoop fs -chmod 1777 /user/spark/applicationHistory
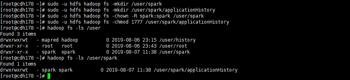
3.修改配置文件/etc/spark/conf/spark-defaults.conf
spark.eventLog.enabled=true
spark.eventLog.dir=hdfs://cdh178.:8020/user/spark/applicationHistory
spark.yarn.historyServer.address=http://cdh178.:18088
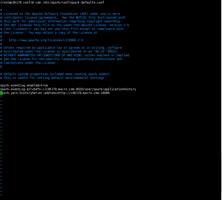
4.启动spark-history-server
systemctl start spark-history-server
systemctl status spark-history-server
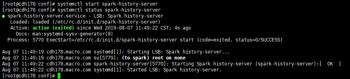
访问Web UI
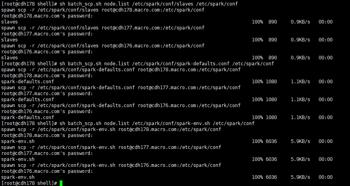
5.修改配置文件并同步到所有节点
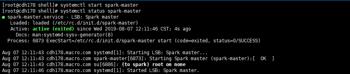
6.启动Spark
在Master节点启动spark-master
systemctl start spark-master
systemctl status spark-master
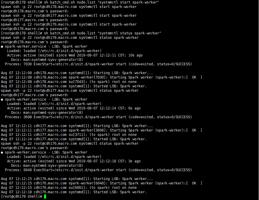
在所有节点启动spark-worker
systemctl start spark-worker
systemctl status spark-worker
7.测试Spark使用
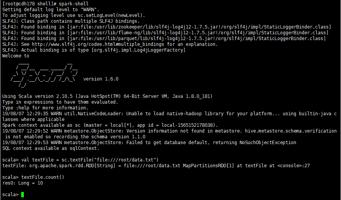
至此Spark安装完成
以上就是关于没root怎么装GG修改器_没root怎么用gg修改器的全部内容,游戏大佬们学会了吗?

gg修改器怎么获得root安卓_gg修改器怎么获得root权限安卓 分类:免root版 7,139人在玩 各位游戏大佬大家好,今天小编为大家分享关于gg修改器怎么获得root安卓_gg修改器怎么获得root权限安卓的内容,轻松修改游戏数据,赶快来一起来看看吧。 虚拟大师 – GPS穿越 ……
下载
华为手机gg修改器root_华为手机gg修改器怎么守护进程 分类:免root版 5,287人在玩 各位游戏大佬大家好,今天小编为大家分享关于华为手机gg修改器root_华为手机gg修改器怎么守护进程的内容,轻松修改游戏数据,赶快来一起来看看吧。 如果你没有废旧的 Android 手……
下载
gg修改器怎样用无root,软件下载:使用无root的GG修改器 分类:免root版 4,426人在玩 如果你是一位游戏玩家,那么你一定知道GG修改器这个工具。它可以让你在游戏中改变一些参数,比如金币数、等级、血量等等。然而,以往使用这个工具需要对手机进行root,这使很多人望……
下载
gg修改器免root变速,下载gg修改器免root变速软件,轻松游戏加速 分类:免root版 2,723人在玩 随着手机游戏的流行,许多玩家都会遇到游戏卡顿、掉帧等问题。此时,加速软件便成为了必备工具之一。其中,gg修改器免root变速软件是一款非常优秀的加速工具,能够让你轻松畅玩各种……
下载
gg修改器怎么用无root,软件推荐:无需root使用的GG修改器 分类:免root版 4,650人在玩 如果你是一名安卓手机用户,那么你一定会知道GG修改器这款神奇的工具。它可以在游戏中修改金币、经验值等数值,让你轻松畅玩游戏。而且最重要的是,现在GG修改器也已经有了无需root……
下载
gg修改器免root版作用,下载能让你享受游戏乐趣的神器gg修改器免root版 分类:免root版 3,302人在玩 如果您是一位游戏爱好者,相信您也应该有过碰到某些游戏关卡太难、金币不够用等问题而感到烦恼的经历。这时候,我们就需要一款强大的游戏修改器来帮助我们解决这些问题。 而今天,……
下载
gg修改器读不出root,下载gg修改器,轻松读取root的神器 分类:免root版 4,177人在玩 在手机游戏中,我们经常需要使用到一些辅助工具,以提升游戏体验。其中,改变游戏内部数据的修改器就是很多玩家所需要的。然而,对于某些需要root权限才能正常运行的游戏来说,普通……
下载
gg修改器root获取华为,下载华为GG修改器root,轻松获取最佳手机性能 分类:免root版 4,705人在玩 在如今的科技时代,手机已经成为人们不可或缺的日常通讯工具。而作为最受欢迎和最先进的智能手机品牌之一,华为早已赢得了无数用户的青睐。但是,即使有最好的硬件和软件,也难免会……
下载
如何gg修改器的root权限,简介 分类:免root版 1,596人在玩 软件下载标题:如何使用GG修改器获取root权限?下载最新版本! GG修改器是一款非常实用的工具,它可以让用户在游戏中轻松修改各种数值和参数。而且,它还能够为用户提供root权限,……
下载
gg修改器怎么启动root_gg修改器如何启动 分类:免root版 4,555人在玩 各位游戏大佬大家好,今天小编为大家分享关于gg修改器怎么启动root_gg修改器如何启动的内容,轻松修改游戏数据,赶快来一起来看看吧。 DNS服务器软件::bind,powerdns,dnsmasq,……
下载