
各位游戏大佬大家好,今天小编为大家分享关于gg修改器汉化免root版_gg修改器免root汉化最新版的内容,轻松修改游戏数据,赶快来一起来看看吧。
作者:trumanyan,腾讯 CSIG 后台开发工程师
网关服务作为统一接入服务,是大部分服务的统一入口。为了避免成功瓶颈,需要对其进行尽可能地优化。因此,特别总结一下 golang 后台服务性能优化的方式,并对网关服务进行优化。
技术背景:
网关服务本身没有业务逻辑处理,仅作为统一入口进行请求转发,因此我们主要关注下列指标
一般后台服务的瓶颈主要为 CPU,内存,IO 操作中的一个或多个。若这三者的负载都不高,但系统吞吐量低,基本就是代码逻辑出问题了。
在代码正常运行的情况下,我们要针对某个方面的高负载进行优化,才能提高系统的性能。golang 可通过 benchmark 加 pprof 来定位具体的性能瓶颈。
go test -v gate_test.go -run=none -bench=. -benchtime=3s -cpuprofile cpu.prof -memprofile mem.prof
golang 具备 GC 功能,而 GC 是最容易被忽视的性能影响因素。尤其是在本地使用 benchmark 测试时,由于时间较短,占用内存较少。往往不会触发 GC。而一旦线上出现 GC 问题,又不太好定位。目前常用的定位方式有两种:
在线上业务中添加net/http/pprof后,可通过下列命令采集 20 秒的 trace 信息
curl http://ip:port/debug/pprof/trace?seconds=20 > trace.out
再通过go tool trace trace.out 即可在本地浏览器中查看 trace 信息。

GC 相关的信息可以在 View trace 中看到
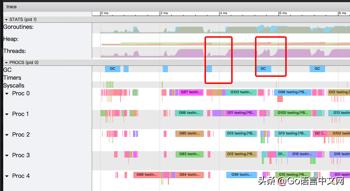
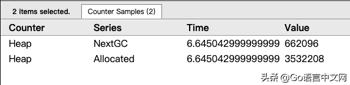
可通过点击 heap 的色块区域,查看 heap 信息。
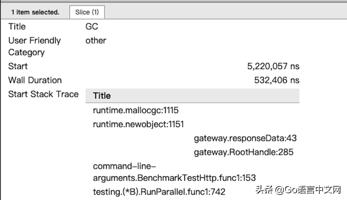
点击 GC 对应行的蓝色色块,查看 GC 耗时及相关回收信息。
通过这两个信息就可以确认是否存在 GC 问题,以及造成高 GC 的可能原因。
trace 的展示仅支持 chrome 浏览器。但是目前常用的 chrome 浏览器屏蔽了 go tool trace 使用的 HTML import 功能。即打开“view trace”时,会出现一片空白。并可以在 console 中看到警告信息:
HTML Imports is deprecated and has now been removed as of M80. See https://www./features/5144752345317376 and https://developers./web/updates/2019/07/ponents-time-to-upgrade for more details.
go tool trace -http=localhost:8001 trace.out
若打开 view trace 还是空白,则检查一下浏览器地址栏中的地址,是否与注册时的一样。即注册用的 localhost 或 127.0.0.1 则地址栏中也要一样。
出现无效甚至降低性能的逻辑。常见的有
未选择恰当的存储方式,常见的有:
并发操作的问题主要出现在资源竞争上,常见的有:
在优化之前,我们需要对 golang 的实现细节有一个简单的了解,才能明白哪些地方有问题,哪些地方可以优化,以及怎么优化。以下内容的详细讲解建议查阅网上优秀的 blog。对语言的底层实现机制最好有个基本的了解,否则有时候掉到坑里都不知道为啥。
Golang 调度是非抢占式多任务处理,由协程主动交出控制权。遇到如下条件时,才有可能交出控制权
因此,若存在较长时间的 for 循环处理,并且循环内没有上述逻辑时,会阻塞住其他的协程调度。在实际编码中一定要注意。
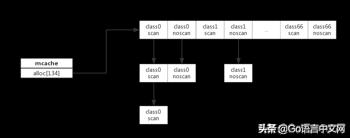
Go 为每个逻辑处理器(P)提供了一个称为mcache的本地内存线程缓存。每个 mcache 中持有 67 个级别的 mspan。每个 msapn 又包含两种:scan(包含指针的对象)和 noscan(不包含指针的对象)。在进行垃圾收集时,GC 无需遍历 noscan 对象。
GC 的工作就是确定哪些内存可以释放,它是通过扫描内存查找内存分配的指针来完成这个工作的。GC 触发时机:
为啥要注意 GC,是因为 GC 时出现 2 次 Stop the world,即停止所有协程,进行扫描操作。若是 GC 耗时高,则会严重影响服务器性能。
注意,golang 中的栈是跟函数绑定的,函数结束时栈被回收。
而变量逃逸就意味着增加了堆中的对象个数,影响 GC 耗时。一般要尽量避免逃逸。
在逃逸分析过程中,凡是发现出现违反上述约定的变量,就将其移到堆中。
type StringHeader struct {
Data uintptr
Len int
}
type SliceHeader struct {
Data uintptr
Len int
Cap int
}
type hmap struct {
count int
flags uint8
B uint8
noverflow uint16
hash0 uint32
buckets unsafe.Pointer
oldbuckets unsafe.Pointer
nevacuate uintptr
extra *mapextra
}
这些是常见会包含指针的对象。尤其是 string,在后台应用中大量出现。并经常会作为 map 的 key 或 value。若数据量较大时,就会引发 GC 耗时上升。同时,我们可以注意到 string 和 slice 非常相似,从某种意义上说它们之间是可以直接互相转换的。这就可以避免 string 和[]byte 之间类型转换时,进行内存拷贝
func String(b []byte) string {
return *(*string)(unsafe.Pointer(&b))
}
func Str2Bytes(s string) []byte {
x := (*[2]uintptr)(unsafe.Pointer(&s))
h := [3]uintptr{x[0], x[1], x[1]}
return *(*[]byte)(unsafe.Pointer(&h))
}
将服务处理的核心逻辑,使用 go test 的 benchmark 加 pprof 来测试。建议上线前,就对整个业务逻辑的性能进行测试,提前优化瓶颈。
一般 http 服务可以通过常见的测试工具进行压测,如 wrk,locust 等。taf 服务则需要我们自己编写一些测试脚本。同时,要注意的是,压测的目的是定位出服务的最佳性能,而不是盲目的高并发请求测试。因此,一般需要逐步提升并发请求数量,来定位出服务的最佳性能点。
注意:由于 taf 平台具备扩容功能,因此为了更准确的测试,我们应该在测试前关闭要测试节点的自动扩容。
为了避免影响后端服务,也为了避免后端服务影响网关自身。因此,我们需要在压测前,将对后端服务的调用屏蔽。
首先看下当前业务的性能指标,使用 wrk 压测网关服务
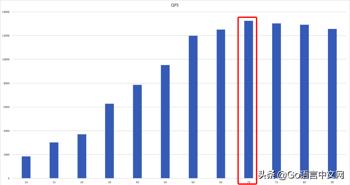
可以看出,在总链接数为 70 的时候,QPS 最高,为 13245。

根据火焰图我们定位出 cpu 占比较高的几个方法为:
为了方便测试,将代码改为本地运行,并通过 benchmark 的方式来对比修改前后的差异。
由于正式环境使用的 golang 版本为 1.12,因此本地测试时,也要使用同样的版本。
Benchmark 50000000 3669 ns/op 4601 B/op 73 allocs/op
查看 cpu 和 memory 的 profile,发现健康度上报的数据结构填充占比较高。这部分逻辑基于 tars 框架实现。暂时忽略,为避免影响其他测试,先注释掉。再看看 benchmark。
Benchmark 500000 3146 ns/op 2069 B/op 55 allocs/op
先查看 json 解析的部分,看看是否有优化空间
//RootHandle view.ReadReq2Json readJsonReq 中进行json解析
type GatewayReqBody struct {
Header GatewayReqBodyHeader `json:"header"`
Payload map[string]interface{} `json:"payload"`
}
func readJsonReq(data []byte, req *model.GatewayReqBody) error {
dataMap := make(map[string]interface{})
err := jsoniter.Unmarshal(data, &dataMap)
...
headerMap, ok := header.(map[string]interface{})
businessName, ok := headerMap["businessName"]
qua, ok := headerMap["qua"]
sessionId, ok := headerMap["sessionId"]
...
payload, ok := dataMap["payload"]
req.Payload, ok = payload.(map[string]interface{})
}
这个函数本质上将 data 解析为 model.GatewayReqBody 类型的结构体。但是这里却存在 2 个问题
func invokeTafServant(resp http.ResponseWriter, gatewayHttpReq *model.GatewayHttpReq) {
...
payloadBytes, err := json.Marshal(gatewayHttpReq.ReqBody.Payload)
if err == nil {
commonReq.Payload = string(payloadBytes)
} else {
responseData(gatewayHttpReq, StatusInternalServerError, "封装json异常", "", resp)
return
}
...
}
后续的使用中,我们可以看到,又将这个 payload 转为 string。因此,我们可以确定,上面的 json 解析是没有意义,同时也会浪费资源(payload 数据量一般不小)。
type GatewayReqBody struct {
Header GatewayReqBodyHeader `json:"header"`
Payload json.RawMessage `json:"payload"`
}
func readJsonReq(data []byte, req *model.GatewayReqBody) error {
err := jsoniter.Unmarshal(data, req)
if err != nil {
return jsonParseErr
}
for k, v := range req.Header.Qua {
req.Header.Qua[k] = v
if len(req.Header.QuaStr) == 0 {
req.Header.QuaStr = k + "=" + v
} else {
req.Header.QuaStr += "&" + k + "=" + v
}
}
return nil
}
func invokeTafServant(resp http.ResponseWriter, gatewayHttpReq *model.GatewayHttpReq) {
commonReq.Payload = string(gatewayHttpReq.ReqBody.Payload)
}
type GatewayRespBody struct {
Header GatewayRespBodyHeader `json:"header"`
Payload map[string]interface{} `json:"payload"`
}
func responseData(gatewayReq *model.GatewayHttpReq, code int32, message string, payload string, resp http.ResponseWriter) {
jsonPayload := make(map[string]interface{})
if len(payload) != 0 {
err := json.Unmarshal([]byte(payload), &jsonPayload)
if err != nil {
...
}
}
body := model.GatewayRespBody{
Header: model.GatewayRespBodyHeader{
Code: code,
Message: message,
},
Payload: jsonPayload,
}
data, err := view.RenderResp("json", &body)
...
resp.WriteHeader(http.StatusOK)
resp.Write(data)
}
同样的,这里的 jsonPayload,也是出现了不必要的 json 解析。我们可以改为
type GatewayRespBody struct {
Header GatewayRespBodyHeader `json:"header"`
Payload json.RawMessage `json:"payload"`
}
body := model.GatewayRespBody{
Header: model.GatewayRespBodyHeader{
Code: code,
Message: message,
},
Payload: encode.Str2Bytes(payload),
}
然后在 view.RenderResp 方法中
func RenderResp(format string, resp interface{}) ([]byte, error) {
if "json" == format {
return jsoniter.Marshal(resp)
}
return nil, errors.New("format error")
}
Benchmark 500000 3326 ns/op 2842 B/op 50 allocs/op
虽然对象 alloc 减少了,但单次操作内存使用增加了,且性能下降了。这就有点奇怪了。我们来对比一下 2 个情况下的 pprof。
可以看出 RootHandle 多了 478.96M 的内存使用。通过 list RootHandle 对比 2 个情况下的内存使用。发现修改后的 RootHandle 中多出了这一行:475.46MB 475.46MB 158: gatewayHttpReq := model.GatewayHttpReq{} 这一般意味着变量 gatewayHttpReq 出现了逃逸。
Benchmark 500000 2994 ns/op 1892 B/op 50 allocs/op
可以看到堆内存使用明显下降。性能也提升了。再看一下 pprof,寻找下个瓶颈。
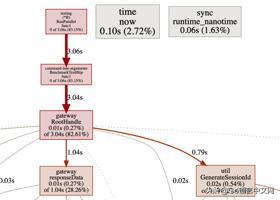
抛开 responeseData(他内部主要是日志打印占比高),占比较高的为 util.GenerateSessionId,先来看看这个怎么优化。
var letterRunes = []rune("0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ")
func RandStringRunes(n int) string {
b := make([]rune, n)
for i := range b {
b[i] = letterRunes[rand.Intn(len(letterRunes))]
}
return string(b)
}
目前的生成方式使用的类型是 rune,但其实用 byte 就够了。另外,letterRunes 是 62 个字符,即最大需要 6 位的 index 就可以遍历完成了。而随机数获取的是 63 位。即每个随机数,其实可以产生 10 个随机字符。而不用每个字符都获取一次随机数。所以我们改为
const (
letterBytes = "0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ"
letterIdxBits = 6
letterIdxMask = 1<<letterIdxBits - 1
letterIdxMax = 63 / letterIdxBits
)
func RandStringRunes(n int) string {
b := make([]byte, n)
for i, cache, remain := n-1, rand.Int63(), letterIdxMax; i >= 0; {
if remain == 0 {
cache, remain = rand.Int63(), letterIdxMax
}
if idx := int(cache & letterIdxMask); idx < len(letterBytes) {
b[i] = letterBytes[idx]
i--
}
cache >>= letterIdxBits
remain--
}
return string(b)
}
Benchmark 1000000 1487 ns/op 1843 B/op 50 allocs/op
一般情况下,都会说将 string 和[]byte 的转换改为 unsafe;以及在字符串拼接时,用 byte.Buffer 代替 fmt.Sprintf。但是网关这里的情况比较特殊,字符串的操作基本集中在打印日志的操作。而 tars 的日志打印本身就是通过 byte.Buffer 拼接的。所以这可以避免。另外,由于日志打印量大,使用 unsafe 转换[]byte 为 string 带来的收益,往往会因为逃逸从而影响 GC,反正会影响性能。因此,不同的场景下,不能简单的套用一些优化方法。需要通过压测及结果分析来判断具体的优化策略。
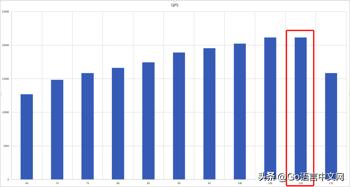
可以看到优化后,最大链接数为 110,最高 QPS 为21153.35。对比之前的13245,大约提升 60%。
从 pprof 中可以看到日志打印,远程日志,健康上报等信息占用较多 cpu 资源,且导致多个数据逃逸(尤其是日志打印)。过多的日志基本等于没有日志。后续可考虑裁剪日志,仅保留出错时的上下文信息。
以上就是关于gg修改器汉化免root版_gg修改器免root汉化最新版的全部内容,游戏大佬们学会了吗?

王者荣耀金币修改器下载 刷金币软件辅助 分类:免root版 7,158人在玩 王者荣耀金币修改器是一个专门为获取金币而设计开发的免费辅助软件,王者荣耀中金币仅次于点券,是一种在游戏中非常重要的货币之一,它可以购买英雄皮肤等让你热血澎湃的东西,必……
下载
王者荣耀不花钱修改器,王者荣耀无限刷点卷器免费 分类:免root版 7,348人在玩 王者荣耀无限刷点卷器免费版是一款王者荣耀不花钱修改器,修改器获取点卷已经不是什么稀奇的事情了,在王者荣耀中有这很多修改器辅助,其中有的好用有的不好用,有的免费有的花钱……
下载
GG免root框架修改器64位,GG免root框架修改器64位,开启无限可能 分类:免root版 3,842人在玩 现在的手机系统越来越复杂,很多应用需要获取 root 权限才能使用更多功能。但是一旦获取了 root 权限,手机的安全性就会受到威胁。因此,有些人选择使用 GG 免root框架修改器64位,……
下载
王者荣耀刷点券修改器 王者荣耀刷点卷外挂破解版下载 分类:免root版 7,318人在玩 王者荣耀刷点券修改器–王者荣耀刷点卷外挂破解版是一个能够获取大量免费点券的神器,此外国非彼外挂。此外挂是一个在手机后台运行的刷点卷修改器没打完一局自动获取数以十……
下载
gg修改器opporoot,下载gg修改器opporoot,轻松解锁手机限制 分类:免root版 2,971人在玩 如果你是一位游戏爱好者或是使用安卓系统的用户,那么你一定会对gg修改器opporoot这款软件感兴趣。这款软件可以帮助你解锁手机的限制,并且让你在游戏中获得更好的体验。 快速修改……
下载
gg修改器怎么同意root,下载一个神奇的工具:GG修改器 分类:免root版 2,661人在玩 如果您是一位游戏玩家,那么您一定知道GG修改器。它是一款非常受欢迎的修改器,为游戏爱好者提供了很多便利。但是,为了让GG修改器正常运行,您需要root权限。那么如何同意root呢?……
下载
怎么在gg修改器开root_如何启动gg修改器 分类:免root版 4,141人在玩 各位游戏大佬大家好,今天小编为大家分享关于怎么在gg修改器开root_如何启动gg修改器的内容,轻松修改游戏数据,赶快来一起来看看吧。 上图的3d视角很多小伙伴都想知道是如何办……
下载
免root修改器gg,免root修改器gg:一款强大的手机游戏辅助工具 分类:免root版 3,867人在玩 在现今的手机游戏市场中,越来越多的游戏需要进行root权限方可使用各种辅助工具,但是root操作需要技术和风险,许多玩家不敢尝试。因此,一些开发者研制了一些非root的辅助工具,其……
下载
无root开GG修改器脚本,软件标题:免Root开GG修改器脚本,轻松修改游戏数据 分类:免root版 4,456人在玩 现在很多手机游戏都有各种各样的限制,比如体力上限、金币数量等等,这些限制让我们玩起来不太舒服。但是现在,我们可以通过一个神奇的软件来解决这些问题——免Root开GG修改器脚本。……
下载
gg修改器root版如何修改,GG修改器Root版:一款轻松修改游戏的神器 分类:免root版 3,205人在玩 GG修改器是一款在游戏中使用的修改器,它可以帮助玩家轻松地修改游戏中的各种数值和属性。而GG修改器Root版则更进一步,允许用户在已经获取root权限的设备上进行更加深度的修改。下……
下载