各位游戏大佬大家好,今天小编为大家分享关于gg修改器游戏源码_gg修改器游戏版的内容,轻松修改游戏数据,赶快来一起来看看吧。
作者:luozhiyun,腾讯IEG后台开发工程师
博客:https://www./archives/475
本文使用的 Go 的源码1.15.7
三色标记法将对象的颜色分为了黑、灰、白,三种颜色。
在垃圾收集器开始工作时,从 GC Roots 开始进行遍历访问,访问步骤可以分为下面几步:
流程大概如下:

下面我们来说说三色标记法会存在的问题。
假设 E 已经被标记过了(变成灰色了),此时 D 和 E 断开了引用,按理来说对象 E/F/G 应该被回收的,但是因为 E 已经变为灰色了,其仍会被当作存活对象继续遍历下去。最终的结果是:这部分对象仍会被标记为存活,即本轮 GC 不会回收这部分内存。
这部分本应该回收 但是没有回收到的内存,被称之为“浮动垃圾”。过程如下图所示:

除了上面多标的问题,还有就是漏标问题。当 GC 线程已经遍历到 E 变成灰色,D变成黑色时,灰色 E 断开引用白色 G ,黑色 D 引用了白色 G。此时切回 GC 线程继续跑,因为 E 已经没有对 G 的引用了,所以不会将 G 放到灰色集合。尽管因为 D 重新引用了 G,但因为 D 已经是黑色了,不会再重新做遍历处理。
最终导致的结果是:G 会一直停留在白色集合中,最后被当作垃圾进行清除。这直接影响到了应用程序的正确性,是不可接受的,这也是 Go 需要在 GC 时解决的问题。
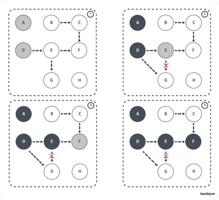
为了解决上面的悬挂指针问题,我们需要引入屏障技术来保障数据的一致性。
A memory barrier, is a type of barrier instruction that causes a central processing unit (CPU) piler to enforce an ordering constraint on memoryoperations issued before and after the barrier instruction. This typically means that operations issued prior to the barrier are guaranteed to be performed before operations issued after the barrier.
内存屏障,是一种屏障指令,它能使CPU或编译器对在该屏障指令之前和之后发出的内存操作强制执行排序约束,在内存屏障前执行的操作一定会先于内存屏障后执行的操作。
那么为了在标记算法中保证正确性,那么我们需要达成下面任意一个条件:
根据操作类型的不同,我们可以将内存屏障分成 Read barrier(读屏障)和 Write barrier(写屏障)两种,在 Go 中都是使用 Write barrier(写屏障),原因在《Uniprocessor Garbage Collection Techniques》也提到了:
If a non copying collector is used the use of a read barrier is an unnecessary expense.there is no need to protect the mutator from seeing an invalid version of a pointer. Write barrier techniques are cheaper, because heap writes are several times mon than heap reads
对于一个不需要对象拷贝的垃圾回收器来说, Read barrier(读屏障)代价是很高的,因为对于这类垃圾回收器来说是不需要保存读操作的版本指针问题。相对来说 Write barrier(写屏障)代码更小,因为堆中的写操作远远小于堆中的读操作。
来下面我们看看 Write barrier(写屏障)是如何做到这一点的。
Go 1.7 之前使用的是 Dijkstra Write barrier(写屏障),使用的实现类似下面伪代码:
writePointer(slot, ptr):
shade(ptr)
*slot = ptr
如果该对象是白色的话,shade(ptr)会将对象标记成灰色。这样可以保证强三色不变性,它会保证 ptr 指针指向的对象在赋值给 *slot 前不是白色。
如下,根对象指向的 D 对象标记成黑色并将 D 对象指向的对象 E 标记成灰色;如果 D 断开对 E 的引用,改成引用 B 对象,那么这时触发写屏障将 B 对象标记成灰色。

Dijkstra Write barrier虽然实现非常的简单,并且也能保证强三色不变性,但是在《Proposal: Eliminate STW stack re-scanning》中也提出了它具有一些缺点:
In particular, it presents a trade-off for pointers on stacks: either writes to pointers on the stack must have write barriers, which is prohibitively expensive, or stacks must be permagrey.
因为栈上的对象在垃圾收集中也会被认为是根对象,所以要么为栈上的对象增加写屏障,但这会大幅度增加写入指针的额外开销;要么当发生栈上的写操作时,将栈标记为恒灰(permagrey)。
Go 1.7 的时候选择的是将栈标记为恒灰,但需要在标记终止阶段 STW 时对这些栈进行重新扫描(re-scan)。原因如下所描述:
without stack write barriers, we can‘t ensure that the stack won’t later contain a reference to a white object, so a scanned stack is only black until its goroutine executes again, at which point it conservatively reverts to grey. Thus, at the end of the cycle, the garbage collector must re-scan grey stacks to blacken them and finish marking any remaining heap pointers.
Yuasa Write barrier 是 Yuasa 在《Real-time garbage collection on general-purpose machines》中提出的一种删除屏障(deletion barrier)技术。其思想是当赋值器从灰色或白色对象中删除白色指针时,通过写屏障将这一行为通知给并发执行的回收器。
该算法会使用如下所示的写屏障保证增量或者并发执行垃圾收集时程序的正确性,伪代码实现如下:
writePointer(slot, ptr)
shade(*slot)
*slot = ptr
为了防止丢失从灰色对象到白色对象的路径,应该假设 *slot 可能会变为黑色, 为了确保 ptr 不会在被赋值到 *slot 前变为白色,shade(*slot) 会先将 *slot 标记为灰色, 进而该写操作总是创造了一条灰色到灰色或者灰色到白色对象的路径,这样删除写屏障就可以保证弱三色不变性,老对象引用的下游对象一定可以被灰色对象引用。

上面说了在 Go 1.7 之前使用的是 Dijkstra Write barrier(写屏障)来保证三色不变性。Go 在重新扫描的时候必须保证对象的引用不会改变,因此会进行暂停程序(STW)、将所有栈对象标记为灰色并重新扫描,这通常会消耗10~100 毫秒的时间。
通过 Proposal: Eliminate STW stack re-scanning https://go./proposal/+/master/design/17503-eliminate-rescan.md 的介绍,可以知道为了消除重新扫描所带来的性能损耗,Go 在 1.8 的时候使用 Hybrid write barrier(混合写屏障),结合了 Yuasa write barrier 和 Dijkstra write barrier ,实现的伪代码如下:
writePointer(slot, ptr):
shade(*slot)
if current stack is grey:
shade(ptr)
*slot = ptr
这样做不仅简化 GC 的流程,同时减少标记终止阶段的重扫成本。混合写屏障的基本思想是:
the write barrier shades the object whose reference is being overwritten, and, if the current goroutine’s stack has not yet been scanned, also shades the reference being installed.
翻译过来就是:对正在被覆盖的对象进行着色,且如果当前栈未扫描完成, 则同样对指针进行着色。
同时,在GC的过程中所有新分配的对象都会立刻变为黑色,在内存分配的时候 gosrc
untimemalloc.go 的 mallocgc 函数中可以看到:
func mallocgc(size uintptr, typ *_type, needzero bool) unsafe.Pointer {
...
dataSize := size
// 获取mcache,用于处理微对象和小对象的分配
c := gomcache()
var x unsafe.Pointer
// 表示对象是否包含指针,true表示对象里没有指针
noscan := typ == nil || typ.ptrdata == 0
// maxSmallSize=32768 32k
if size <= maxSmallSize {
// maxTinySize= 16 bytes
if noscan && size < maxTinySize {
...
} else {
...
}
// 大于 32 Kb 的内存分配,通过 mheap 分配
} else {
...
}
...
// 在 GC 期间分配的新对象都会被标记成黑色
if gcphase != _GCoff {
gcmarknewobject(span, uintptr(x), size, scanSize)
}
...
return x
}
在垃圾收集的标记阶段,将新建的对象标记成黑色,防止新分配的栈内存和堆内存中的对象被错误地回收。
GC 相关的代码在runtime/mgc.go文件下。通过注释介绍我们可以知道 GC 一共分为4个阶段:
需要注意的是,上面提到了 mutator assists,因为有一种情况:
during the collection that the Goroutine dedicated to GC will not finish the Marking work before the heap memory in-use reaches its limit
因为 GC 标记的工作是分配 25% 的 CPU 来进行 GC 操作,所以有可能 GC 的标记工作线程比应用程序的分配内存慢,导致永远标记不完,那么这个时候就需要应用程序的线程来协助完成标记工作:
If the collector determines that it needs to slow down allocations, it will recruit the application Goroutines to assist with the Marking work. This is called a Mutator Assist. One positive side effect of Mutator Assist is that it helps to finish the collection faster.
下次 GC 的时机可以通过一个环境变量 GOGC 来控制,默认是 100 ,即增长 100% 的堆内存才会触发 GC。
This value represents a ratio of how much new heap memory can be allocated before the next collection has to start.
官方的解释是,如果当前使用了 4M 内存,那么下次 GC 将会在内存达到 8M 的时候。下面我们看看一个具体的例子:
package main
import (
"fmt"
)
func main() {
fmt.Println("start.")
container := make([]int, 8)
fmt.Println("> loop.")
for i := 0; i < 32*1000*1000; i++ {
container = append(container, i)
}
fmt.Println("< loop.")
}
需要注意的是,大家在做实验的时候推荐使用 Linux 环境,如果没有 Linux 环境可以像我一样在 win10 下跑了一个虚拟机,然后用 vscode 远程到 Linux 进行实验的,大家不妨试一下。
编译好之后,可以使用 gctrace 跟踪 GC 情况:
[root@localhost gotest]# go build main.go
[root@localhost gotest]# GODEBUG=gctrace=1 ./main
start.
> loop.
gc 1 @0.004s 4%: 0.22+1.4+0.021 ms clock, 1.7+0.009/0.40/0.073+0.16 ms cpu, 4->5->1 MB, 5 MB goal, 8 P
gc 2 @0.006s 4%: 0.10+1.6+0.020 ms clock, 0.83+0.12/0/0+0.16 ms cpu, 4->6->1 MB, 5 MB goal, 8 P
gc 3 @0.009s 16%: 0.035+5.5+2.2 ms clock, 0.28+0/0.47/0.007+18 ms cpu, 4->15->15 MB, 5 MB goal, 8 P
...
< loop.
上面展示了 3 次 GC 的情况,下面我们看看具体的含义是什么:
gc 1 @0.004s 4%: 0.22+1.4+0.021 ms clock, 1.7+0.009/0.40/0.073+0.16 ms cpu, 4->5->1 MB, 5 MB goal, 8 P
gc 1 :程序启动以来第1次GC
@0.004s:距离程序启动到现在的时间
4%:当目前为止,GC 的标记工作所用的CPU时间占总CPU的百分比
垃圾回收的时间
0.22 ms:标记开始 STW 时间
1.4 ms:并发标记时间
0.021 ms:标记终止 STW 时间
垃圾回收占用cpu时间
1.7 ms:标记开始 STW 时间
0.009 ms:mutator assists占用的时间
0.40 ms:标记线程占用的时间
0.073 ms:idle mark workers占用的时间
0.16 ms:标记终止 STW 时间
内存
4 MB:标记开始前堆占用大小
5 MB:标记结束后堆占用大小
1 MB:标记完成后存活堆的大小
5 MB goal:标记完成后正在使用的堆内存的目标大小
8 P:使用了多少处理器

从上面的 GC 内存信息中可以看到,在 GC 标记开始之前的时候堆大小是 4MB,由于标记工作是并发进行的,所以当标记完成的时候堆中被使用的大小是 5MB,这表示有 1MB 的内存分配是发生在 GC 期间。最后我们可以看到 GC 标记完之后存活的堆大小只有 1MB,这也表示可以在堆占用内存达到 2MB 的时候开始下一轮 GC。
从上面我们可以看到 Goal 部分的内存大小是 5MB,和实际的 In-Use After 部分的内存占用情况相等,但是在很多复杂的情况下是不相等的,因为 Goal 部分的内存大小是基于当前内存的使用情况进行推算的。
the goal is calculated based on the current amount of the heap memory in-use, the amount of heap memory marked as live, and timing calculations about the additional allocations that will occur while the collection is running.
触发 GC 条件是由 gcTrigger.test来进行校验的,下面我们看看 gcTrigger.test如何判定是否需要触发垃圾收集:
func (t gcTrigger) test() bool {
if !memstats.enablegc || panicking != 0 || gcphase != _GCoff {
return false
}
switch t.kind {
case gcTriggerHeap:
// 堆内存的分配达到达控制器计算的触发堆大小
return memstats.heap_live >= memstats.gc_trigger
case gcTriggerTime:
if gcpercent < 0 {
return false
}
lastgc := int64(atomic.Load64(&memstats.last_gc_nanotime))
// 如果一定时间内没有触发,就会触发新的循环
return lastgc != 0 && t.now-lastgc > forcegcperiod
case gcTriggerCycle:
// 要求启动新一轮的GC, 已启动则跳过
return int32(t.n-work.cycles) > 0
}
return true
}
gcTriggerTime 的触发时间是由 forcegcperiod 决定的,默认是2分钟。下面我们主要看看堆内存大小触发 GC 的情况。
gcTriggerHeap 堆内存的分配达到达控制器计算的触发堆大小,heap_live 值会在内存分配的时候进行计算,gc_trigger 的计算是在 runtime.gcSetTriggerRatio函数中进行的。
func gcSetTriggerRatio(triggerRatio float64) {
// gcpercent 由环境变量 GOGC 决定
if gcpercent >= 0 {
// 默认是 1
scalingFactor := float64(gcpercent) / 100
// 最大的 maxTriggerRatio 是 0.95
maxTriggerRatio := 0.95 * scalingFactor
if triggerRatio > maxTriggerRatio {
triggerRatio = maxTriggerRatio
}
// 最大的 minTriggerRatio 是 0.6
minTriggerRatio := 0.6 * scalingFactor
if triggerRatio < minTriggerRatio {
triggerRatio = minTriggerRatio
}
} else if triggerRatio < 0 {
triggerRatio = 0
}
memstats.triggerRatio = triggerRatio
trigger := ^uint64(0)
if gcpercent >= 0 {
// 当前标记存活的大小乘以1+系数triggerRatio
trigger = uint64(float64(memstats.heap_marked) * (1 + triggerRatio))
...
}
memstats.gc_trigger = trigger
...
}
gcSetTriggerRatio 函数会根据计算出来的 triggerRatio 来获取下次触发 GC 的堆大小是多少。triggerRatio 每次GC后都会调整,计算 triggerRatio 的函数是 gcControllerState.endCycle中进行的,gcControllerState.endCycle 会在 MarkDone 中被调用的。
func (c *gcControllerState) endCycle() float64 {
const triggerGain = 0.5
// 目标Heap增长率 = (下次 GC 完后堆大小 - 堆存活大小)/ 堆存活大小
goalGrowthRatio := float64(memstats.next_gc-memstats.heap_marked) / float64(memstats.heap_marked)
// 实际Heap增长率, 等于总大小/存活大小-1
actualGrowthRatio := float64(memstats.heap_live)/float64(memstats.heap_marked) - 1
// GC标记阶段的使用时间
assistDuration := nanotime() - c.markStartTime
// GC标记阶段的CPU占用率, 目标值是0.25
utilization := gcBackgroundUtilization
// Add assist utilization; avoid divide by zero.
if assistDuration > 0 {
// assistTime 是G辅助GC标记对象所使用的时间合计
// 额外的CPU占用率 = 辅助GC标记对象的总时间 / (GC标记使用时间 * P的数量)// 额外的CPU占用率 = 辅助GC标记对象的总时间 / (GC标记使用时间 * P的数量)
utilization += float64(c.assistTime) / float64(assistDuration*int64(gomaxprocs))
}
// 触发系数偏移值 = 目标增长率 - 原触发系数 - CPU占用率 / 目标CPU占用率 * (实际增长率 - 原触发系数)
triggerError := goalGrowthRatio - memstats.triggerRatio - utilization/gcGoalUtilization*(actualGrowthRatio-memstats.triggerRatio)
// 根据偏移值调整触发系数, 每次只调整偏移值的一半
triggerRatio := memstats.triggerRatio + triggerGain*triggerError
return triggerRatio
}
对于 triggerRatio 总体来说还是比较复杂的,我们可以根据偏离值来得知:
通过上面的分析,也解释了为什么在 GODEBUG=gctrace=1分析中明明堆内存还没达到 2倍却被提前执行了,主要还是受 triggerError 偏移量的影响导致的。
我们在测试的时候可以调用 runtime.GC来手动的触发 GC。但实际上,触发 GC 的入口一般不会手动调用。正常触发 GC 应该是在申请内存时会调用 runtime.mallocgc或者是 Go 后台的监控线程 sysmon 定时检查调用 runtime.forcegchelper。
func GC() {
// 获取 GC 循环次数
n := atomic.Load(&work.cycles)
// 等待上一个循环的标记终止、标记和清除终止阶段完成
gcWaitOnMark(n)
// 触发新一轮的 GC
gcStart(gcTrigger{kind: gcTriggerCycle, n: n + 1})
// 同上
gcWaitOnMark(n + 1)
// 等待清理全部待处理的内存管理单元
for atomic.Load(&work.cycles) == n+1 && sweepone() != ^uintptr(0) {
sweep.nbgsweep++
// 让出 P
Gosched()
}
for atomic.Load(&work.cycles) == n+1 && atomic.Load(&mheap_.sweepers) != 0 {
Gosched()
}
mp := acquirem()
cycle := atomic.Load(&work.cycles)
if cycle == n+1 || (gcphase == _GCmark && cycle == n+2) {
// 将该阶段的堆内存状态快照发布出来( heap profile)
mProf_PostSweep()
}
releasem(mp)
}
下图是比较完整的GC流程,可作为看源码时候的导航:

gcStart 函数比较长,下面分段来看看 gcStart:
func gcStart(trigger gcTrigger) {
...
// 验证垃圾收集条件 ,并清理已经被标记的内存单元
for trigger.test() && sweepone() != ^uintptr(0) {
sweep.nbgsweep++
}
// 获取全局的 startSema信号量
semacquire(&work.startSema)
// 再次验证垃圾收集条件
if !trigger.test() {
semrelease(&work.startSema)
return
}
// 检查是不是手动调用了 runtime.GC
work.userForced = trigger.kind == gcTriggerCycle
semacquire(&gcsema)
semacquire(&worldsema)
// 启动后台标记任务
gcBgMarkStartWorkers()
// 重置标记相关的状态
systemstack(gcResetMarkState)
// work 初始化工作
work.stwprocs, work.maxprocs = gomaxprocs, gomaxprocs
if work.stwprocs > ncpu {
work.stwprocs = ncpu
}
work.heap0 = atomic.Load64(&memstats.heap_live)
work.pauseNS = 0
work.mode = mode
// 记录开始时间
now := nanotime()
work.tSweepTerm = now
work.pauseStart = now
// 暂停程序 STW
systemstack(stopTheWorldWithSema)
// 在并发标记前,确保清理结束
systemstack(func() {
finishsweep_m()
})
// 清理sched.sudogcache 以及 sync.Pools
clearpools()
// GC 次数
work.cycles++
// 在开始 GC 之前清理控制器的状态,标记新一轮GC已开始
gcController.startCycle()
work.heapGoal = memstats.next_gc
// 设置全局变量中的GC状态为_GCmark
// 然后启用写屏障
setGCPhase(_GCmark)
// 初始化后台扫描需要的状态
gcBgMarkPrepare() // Must happen before assist enable.
// 扫描栈上、全局变量等根对象并将它们加入队列
gcMarkRootPrepare()
// 标记所有tiny alloc等待合并的对象
gcMarkTinyAllocs()
// 启用 mutator assists(协助线程)
atomic.Store(&gcBlackenEnabled, 1)
// 记录标记开始的时间
gcController.markStartTime = now
mp = acquirem()
// 启动程序,后台任务也会开始标记堆中的对象
systemstack(func() {
now = startTheWorldWithSema(trace.enabled)
// 记录停止了多久, 和标记阶段开始的时间
work.pauseNS += now - work.pauseStart
work.tMark = now
})
semrelease(&worldsema)
...
}
下面这张图显示了 gcStart 过程中状态变化,以及 STW 停顿的方法,写屏障启用的周期:

上面只是粗略的说一下各个函数的作用,下面来分析一些重要的函数。
func (c *gcControllerState) startCycle() {
c.scanWork = 0
c.bgScanCredit = 0
c.assistTime = 0
c.dedicatedMarkTime = 0
c.fractionalMarkTime = 0
c.idleMarkTime = 0
// 设置 next_gc 最小值
if memstats.next_gc < memstats.heap_live+1024*1024 {
memstats.next_gc = memstats.heap_live + 1024*1024
}
// gcBackgroundUtilization 默认是 0.25
// 是GC所占的P的目标值
totalUtilizationGoal := float64(gomaxprocs) * gcBackgroundUtilization
// dedicatedMarkWorkersNeeded 等于P的数量的25% 加上 0.5 去掉小数点
c.dedicatedMarkWorkersNeeded = int64(totalUtilizationGoal + 0.5)
utilError := float64(c.dedicatedMarkWorkersNeeded)/totalUtilizationGoal - 1
const maxUtilError = 0.3
if utilError < -maxUtilError || utilError > maxUtilError {
if float64(c.dedicatedMarkWorkersNeeded) > totalUtilizationGoal {
c.dedicatedMarkWorkersNeeded--
}
// 是 gcMarkWorkerFractionalMode 的任务所占的P的目标值(
c.fractionalUtilizationGoal = (totalUtilizationGoal - float64(c.dedicatedMarkWorkersNeeded)) / float64(gomaxprocs)
} else {
c.fractionalUtilizationGoal = 0
}
if debug.gcstoptheworld > 0 {
c.dedicatedMarkWorkersNeeded = int64(gomaxprocs)
c.fractionalUtilizationGoal = 0
}
for _, p := range allp {
p.gcAssistTime = 0
p.gcFractionalMarkTime = 0
}
// 计算协助GC的参数
c.revise()
}
这里需要注意的是 dedicatedMarkWorkersNeeded 与 fractionalUtilizationGoal 的计算过程,这个会在计算 work 工作模式的用到。
func gcMarkTinyAllocs() {
for _, p := range allp {
// 标记各个 P 中的 mcache 中的 tiny
c := p.mcache
if c == nil || c.tiny == 0 {
continue
}
_, span, objIndex := findObject(c.tiny, 0, 0)
gcw := &p.gcw
// 标记存活对象,并把它加到 gcwork 标记队列
greyobject(c.tiny, 0, 0, span, gcw, objIndex)
}
}
tiny block 这个数据结构也在内存分配那一节讲过了,这里主要是会把所有 P 中的 mcache 中的 tiny 找到并进行标记,然后把它加到 gcwork 标记队列,至于什么是 gcwork 标记队列,我们下面在执行标记的地方会讲到。
在设置 GC 阶段标记的时候会根据当前的设置的值来判断是否需要开启 write Barrier :
func setGCPhase(x uint32) {
atomic.Store(&gcphase, x)
writeBarrier.needed = gcphase == _GCmark || gcphase == _GCmarktermination
writeBarrier.enabled = writeBarrier.needed || writeBarrier.cgo
}
编译器会在srcpileinternalssawritebarrier.go中调用 writebarrier 函数,就如同它的注释所说:
// writebarrier pass inserts write barriers for store ops (Store, Move, Zero) // when necessary (the condition above). It rewrites store ops to branches // and runtime calls, like // // if writeBarrier.enabled { // gcWriteBarrier(ptr, val) // Not a regular Go call // } else { // *ptr = val // }
在执行 Store, Move, Zero 等汇编操作的时候加入写屏障。
我们可以通过 dlv 断点找到 gcWriteBarrier 汇编代码的位置在 go/src/runtime/asm_amd64.s:1395。该汇编函数会调用 runtime.wbBufFlush将 write barrier 的缓存任务添加到 GC 的工作队列中进行处理。
func wbBufFlush(dst *uintptr, src uintptr) {
...
systemstack(func() {
...
wbBufFlush1(getg().m.p.ptr())
})
}
func wbBufFlush1(_p_ *p) {
// 获取缓存的指针
start := uintptr(unsafe.Pointer(&_p_.wbBuf.buf[0]))
n := (_p_.wbBuf.next - start) / unsafe.Sizeof(_p_.wbBuf.buf[0])
ptrs := _p_.wbBuf.buf[:n]
_p_.wbBuf.next = 0
gcw := &_p_.gcw
pos := 0
for _, ptr := range ptrs {
// 查找到对象
obj, span, objIndex := findObject(ptr, 0, 0)
if obj == 0 {
continue
}
mbits := span.markBitsForIndex(objIndex)
// 判断是否已被标记
if mbits.isMarked() {
continue
}
// 进行标记
mbits.setMarked()
// 标记 span.
arena, pageIdx, pageMask := pageIndexOf(span.base())
if arena.pageMarks[pageIdx]&pageMask == 0 {
atomic.Or8(&arena.pageMarks[pageIdx], pageMask)
}
if span.spanclass.noscan() {
gcw.bytesMarked += uint64(span.elemsize)
continue
}
ptrs[pos] = obj
pos++
}
// 将对象加入到 gcWork队列中
gcw.putBatch(ptrs[:pos])
// 重置 write barrier 缓存
_p_.wbBuf.reset()
}
写屏障这里其实也是和并发标记是一样的套路,可以看完并发标记再过来看。wbBufFlush1 会遍历write barrier 缓存,然后调用 findObject 查找到对象之后使用标志位进行标记,最后将对象加入到 gcWork队列中进行扫描,并 重置 write barrier 缓存。
stopTheWorldWithSema 与 startTheWorldWithSema 是一对用于暂停和恢复程序的核心函数。
func stopTheWorldWithSema() {
_g_ := getg()
lock(&sched.lock)
sched.ait = gomaxprocs
// 标记 gcwaiting,调度时看见此标记会进入等待
atomic.Store(&sched.gcwaiting, 1)
// 发送抢占信号
preemptall()
// 暂停当前 P
_g_.m.p.ptr().status = _Pgcstop // Pgcstop is only diagnostic.
sched.ait--
// 遍历所有的 P ,修改 P 的状态为 _Pgcstop 停止运行
for _, p := range allp {
s := p.status
if s == _Psyscall && atomic.Cas(&p.status, s, _Pgcstop) {
if trace.enabled {
traceGoSysBlock(p)
traceProcStop(p)
}
p.syscalltick++
sched.ait--
}
}
// 停止空闲的 P 列表
for {
p := pidleget()
if p == nil {
break
}
p.status = _Pgcstop
sched.ait--
}
wait := sched.ait > 0
unlock(&sched.lock)
if wait {
for {
// 等待 100 us
if notetsleep(&sched.stopnote, 100*1000) {
noteclear(&sched.stopnote)
break
}
// 再次进行发送抢占信号
preemptall()
}
}
// 安全检测
bad := ""
if sched.ait != 0 {
bad = "stopTheWorld: not stopped (ait != 0)"
} else {
for _, p := range allp {
if p.status != _Pgcstop {
bad = "stopTheWorld: not stopped (status != _Pgcstop)"
}
}
}
if atomic.Load(&freezing) != 0 {
lock(&deadlock)
lock(&deadlock)
}
if bad != "" {
throw(bad)
}
}
这个方法会通过sched.ait来检测是否所有的 P 都已暂停。首先会通过调用 preemptall 发送抢占信号进行抢占所有运行中的 G,然后遍历 P 将所有状态为 _Psyscall、空闲的 P 都暂停,如果仍有需要停止的P, 则等待它们停止。
func startTheWorldWithSema(emitTraceEvent bool) int64 {
mp := acquirem() // disable preemption because it can be holding p in a local var
// 判断收到的 netpoll 事件并添加对应的G到待运行队列
if netpollinited() {
list := netpoll(0) // non-blocking
injectglist(&list)
}
lock(&sched.lock)
procs := gomaxprocs
if newprocs != 0 {
procs = newprocs
newprocs = 0
}
// 扩容或者缩容全局的处理器
p1 := procresize(procs)
// 取消GC等待标记
sched.gcwaiting = 0
// 如果 sysmon (后台监控线程) 在等待则唤醒它
if sched.sysmonwait != 0 {
sched.sysmonwait = 0
notewakeup(&sched.sysmonnote)
}
unlock(&sched.lock)
// 唤醒有可运行任务的P
for p1 != nil {
p := p1
p1 = p1.link.ptr()
if p.m != 0 {
mp := p.m.ptr()
p.m = 0
if mp.nextp != 0 {
throw("startTheWorld: inconsistent mp->nextp")
}
mp.nextp.set(p)
notewakeup(&mp.park)
} else {
// Start M to run P
newm(nil, p, -1)
}
}
startTime := nanotime()
if emitTraceEvent {
traceGCSTWDone()
}
// 如果有空闲的P,并且没有自旋中的M则唤醒或者创建一个M
wakep()
releasem(mp)
return startTime
}
startTheWorldWithSema 就显得简单的多,首先从 netpoller 中获取待处理的任务并加入全局队列;然后遍历 P 链表,唤醒有可运行任务的P。
以上就是关于gg修改器游戏源码_gg修改器游戏版的全部内容,游戏大佬们学会了吗?

没root能用gg修改器吗,软件下载:没root能用gg修改器吗? 分类:免root版 5,209人在玩 GG修改器是一款非常出色的游戏辅助工具,它可以帮助玩家在游戏中实现自己想要的效果,比如无限金币、无限钻石等。但是,使用GG修改器通常需要对设备进行ROOT权限的获取,这对很多用……
下载
怎么在gg修改器开root_如何启动gg修改器 分类:免root版 4,916人在玩 各位游戏大佬大家好,今天小编为大家分享关于怎么在gg修改器开root_如何启动gg修改器的内容,轻松修改游戏数据,赶快来一起来看看吧。 上图的3d视角很多小伙伴都想知道是如何办……
下载
gg修改器去免root权限,下载一个神奇的软件GG修改器,免Root操作实现游戏外挂 分类:免root版 5,495人在玩 现在的手游越来越火爆,但是有些玩家想要实现游戏中的外挂却需要进行Root操作,对于不懂技术的小白来说这无疑增加了很大的难度。但是有了GG修改器,这个问题就得到了完美解决。 什……
下载
gg修改器怎么去掉root_彻底删除gg修改器 分类:免root版 6,313人在玩 各位游戏大佬大家好,今天小编为大家分享关于gg修改器怎么去掉root_彻底删除gg修改器的内容,轻松修改游戏数据,赶快来一起来看看吧。 超级用户权限是安卓系统的最高权限,仅适用于……
下载
gg修改器如何安装root,软件下载:使用 GG 修改器安装 Root 分类:免root版 3,307人在玩 GG 修改器是一款非常实用的应用程序,它可以帮助你轻松地修改游戏数据和参数,从而实现各种有趣的效果。其中一个最受欢迎的功能就是能够帮助你安装 Root 权限。 什么是 Root 权限?……
下载
gg修改器怎么才免ROOT,GG修改器免ROOT版软件下载 分类:免root版 5,459人在玩 GG修改器是一款广受欢迎的游戏修改工具,它可以帮助玩家在游戏中获得更多的资源和优势。但是,传统的GG修改器需要手机ROOT才能使用,对于不想ROOT手机的用户来说,这无疑是一个麻烦……
下载
MC租赁服GG修改器免root,下载MC租赁服GG修改器免root,让你畅玩无忧 分类:免root版 5,749人在玩 如果你是一名热爱玩游戏的玩家,那么你一定会遇到各种各样的问题,比如说游戏中任务难度太高、装备不足等等。这时候,我们就需要一些软件来帮助我们解决这些问题。今天,我要介绍的……
下载
王者荣耀自定义修改器下载,王者荣耀自定义皮肤修改器 分类:免root版 8,269人在玩 欢迎各位小伙伴的到来!你还在为上不去王者苦恼吗?今天这款王者荣耀自定义修改器是一款帅爆了的多功能皮肤修改应用。王者荣耀自定义修改软件支持王者荣耀自定义修改战区、王者荣耀……
下载
GG修改器怎么能免root,GG修改器:免Root实现游戏定制化 分类:免root版 4,809人在玩 对于手机游戏玩家来说,想要在游戏中获得更高的成就和更好的游戏体验,往往需要通过修改游戏数据进行优化。而要想修改游戏数据,通常需要获得Root权限。但是对于一些不太懂技术或者……
下载
gg修改器 无root,下载最好用的gg修改器,无root随心所欲 分类:免root版 4,628人在玩 现在的手游市场非常火爆,各种类型的游戏层出不穷。但是有些游戏需要充值才能获得更好的游戏体验,这对于一些玩家来说可能不太划算。那么有没有办法可以解决这个问题呢?答案是肯定……
下载