各位游戏大佬大家好,今天小编为大家分享关于gg游戏修改器新手使用_gg修改器新手教程,用详细过程教你入门,称为游戏高手的内容,轻松修改游戏数据,赶快来一起来看看吧。
GNU计划,又译为“革奴计划”,它的目标是创建一套完全自由的操作系统GNU,并且其内容软件完全以GPL方式发布。这个操作系统是GNU计划的主要目标,名称来自GNU’s Not Unix!的递归缩写,因为GNU的设计类似Unix,但它不包含具著作权的Unix代码。
作为操作系统,GNU的发展仍未完成,其中最大的问题是具有完备功能的内核尚未被开发成功。GNU的内核,称为Hurd,是自由软件基金会发展的重点,但是其发展尚未成熟。在实际使用上,多半使用Linux内核作为系统核心。

Linux操作系统包含了Linux内核与其他自由软件项目中的GNU组件和软件,可以被称为GNU/Linux。
GNU组件及软件非常丰富,如:

GCC原名为GNU C语言编译器(GNU C Compiler),只能处理C语言。但其很快扩展,变得可处理C++,后来又扩展为能够支持更多编程语言,如Fortran、Pascal、Objective -C、Java、Ada、Go以及各类处理器架构上的汇编语言等,所以改名GNU编译器套件(GNU Compiler Collection)。
glibc是GNU发布的libc库,即c运行库。glibc是linux系统中最底层的api,几乎其它任何运行库都会依赖于glibc。glibc除了封装linux操作系统所提供的系统服务外,它本身也提供了许多其它一些必要功能服务的实现。
glibc与libc的关系:
glibc 和 libc 都是 Linux 下的 C 函数库。libc 是 Linux 下的 ANSI C 函数库;glibc 是 Linux 下的 GUN C 函数库。
ANSI C 函数库是基本的 C 语言函数库,包含了 C 语言最基本的库函数。这个库可以根据头文件划分为 15 个部分,其中包括:

glibc是linux下面c标准库的实现,即GNU C Library。glibc本身是GNU旗下的C标准库,后来逐渐成为了Linux的标准c库,而Linux下原来的标准c库Linux libc逐渐不再被维护。
Linux下面的标准c库不仅有这一个,如uclibc、klibc,以及上面被提到的Linux libc,但是glibc无疑是用得最多的。glibc在/lib目录下的.so文件为libc.so.6。
libc 实际上是一个泛指。凡是符合实现了 C 标准规定的内容,都是一种 libc 。glibc 是 GNU 组织对 libc 的一种实现。它是 unix/linux 的根基之一。嵌入式行业里还常用 uClibc ,是一个迷你版的 libc 。
coreutils 是GNU下的一个软件包,这个软件包中包含了很多程序,如ls、mv等程序。常用的如:

GDB(GNU symbolic debugger)是 GNU Project 调试器。
GDB 可以做四种主要的事情(以及支持这些事情的其他事情)来帮助你捕获行为中的错误:
这些程序可能与GDB(本机)在同一台计算机上执行,在另一台计算机(远程)上或在模拟器上执行。
GNU binutils是一组二进制工具集。包含的工具有:

GNU系统包括很多软件包,还包括非GNU的自由软件。具体的介绍可以上gnu官网(http://www.gnu.org/software/)上查看:


以上是对GNU及其内容做了一个简单的介绍,下面对GUN相关的内容做一些实例分享:
使用gcc工具集将C语言源代码生成可执行程序需要经过4个步骤:预处理、编译、汇编、链接。如:
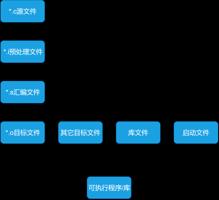
首先,调用预处理器cpp进行预处理,对源代码.c文件中的文件包含(include)、预编译语句(如宏定义define等)进行分析,生成.i文件。
接着调用编译器gcc进行编译,输入上一步的.i文件,输出.s汇编文件。
然后调用汇编器as将.s为后缀的汇编语言文件处理生成以.o为后缀的目标文件。
当所有的目标文件都生成之后,调用链接器ld来进行链接生成可执行文件或库文件。这一节我们先看生成可执行文件,下一节再看如何生成库文件。
其中上图中表明的-E、-S、-c为gcc编译参数。gcc的基本用法如下:
gcc [options] [filenames]
下面以一个实例来演示将C语言源代码生成可执行程序的过程。
示例代码hello.c:
#include <stdio.h>
int main(void)
{
printf("Hello gcc
");
return 0;
}
使用预处理器cpp把源文件hello.c经过预处理生成hello.i文件,预处理用于将所有的#include头文件以及宏定义替换成其真正的内容。
预处理的命令为:
gcc -E hello.c -o hello.i
上述命令中-E是让编译器在预处理之后就退出,不进行后续编译过程;-o是指定输出文件名。
预处理之后得到的仍然是文本文件。hello.i文件部分内容截图如下:

使用编译器将预处理文件hello.i编译成汇编文件hello.s。
编译的命令为:
gcc -S hello.i -o hello.s
上述命令中-S让编译器在编译之后停止,不进行后续过程;-o是指定输出文件名。汇编文件hello.s是文本文件,部分内容截图如下:

使用汇编器将汇编文件hello.s转换成目标文件hello.o。
汇编过程的命令为:
gcc -c hello.s -o hello.o
上述命令中-c、-o让汇编器把汇编文件hello.s转换成目标文件hello.o。目标文件hello.o是二进制文件。这时候我们可以使用如下命令查看hello.o的格式:
file hello.o
显示的内容:
hello.o: ELF 64-bit LSB relocatable, x86-64, version 1 (SYSV), not stripped
可以看到,hello.o是个ELF(Executable and Linking Format,可执行链接格式)格式文件。另外,hello.o是个二进制文件,使用vscode打开可能会出现乱码,可以安装一个Binary插件。部分内容截图如下:

链接过程使用链接器将该目标文件与其他目标文件、库文件、启动文件等链接起来生成可执行文件。
命令为:
gcc hello.o -o hello
综上:

上一节的第(4)步的链接过程分为两种。一种是静态链接,另外一种是动态链接。它们的区别如:
优点:代码装载速度快,执行速度略比动态链接库快。
缺点:使用静态链接生成的可执行文件体积较大,包含相同的公共代码,造成浪费。
优点:生成的可执行文件较静态链接生成的可执行文件小。
缺点:速度比静态链接慢;使用动态链接库的应用程序不是自完备的,需要依赖相关库。
初学,理解不了?没关系,分享一个易懂的比喻:
把链接过程看做我们平时学习时做笔记的过程。我们平时学习时准备一本笔记本专门记录我们的学习笔记,比如在某本书的某一页上看到一个很好很有用的知识,这时候我们有两种方法记录在我们的笔记本上,一种是直接把那一页的内容全部抄写一遍到笔记本上(静态链接);另一种是我们在笔记本上做个简单的记录(动态链接),比如写上:xxx知识点在《xxx》的xxx页。
从这两种方法中我们可以很清楚地知道两种方式的特点,第一种方式的优点就是我们在复习的时候就很方便,不用翻阅其它书籍了,但是缺点也很明显,就是占用笔记本的空间很多,这种方法很快就把我们的笔记本给写满了。第二种方式的优点就是很省空间,缺点就是每当我们复习的时候,手头上必须备着相关的参考书籍,比如我们去教室复习的时候,就得背着一大摞书去复习,这样我们复习的效率可能就没有那么高了。
这对应到我们的动态链接与静态链接上是不是就很好理解了。
下面看看具体实例:
文件1(main.c):
#include "hello.h"
int main(void)
{
print_hello();
return 0;
}
文件2(hello.c):
#include "hello.h"
void print_hello(void)
{
printf("hello world
");
}
文件3(hello.h):
#ifndef __HELLO_H
#define __HELLO_H
#include <stdio.h>
void print_hello(void);
#endif
① 演示动态链接
首先,将源文件生成目标文件(*.o),命令:
gcc -c main.c hello.c
在Linux中,动态库的扩展名一般为.so。我们把上面生成的hello.o文件生成相应的动态库,命令:
gcc -shared hello.o -o libhello.so
使用链接动态库的方式生成可执行程序,命令:
gcc main.o -L. -lhello -o hello_d_lib_test
这里的-L.的含义是在搜索库文件时包含当前目录,-lhello的含义是链接名称为libhello.so的动态库。
此时,运行hello_d_lib_test程序,可能会出现如下错误:
./hello_d_lib_test: error while loading shared libraries: libhello.so: cannot open shared object file: No such file or directory
这是因为找不到共享库文件libhello.so,加载失败。因为一般情况下Linux会在/usr/lib路径中搜索需要用到的库,而libhello.so库并不在这个路径下。
解决方法有如下几种:
我们这里作为测试,使用临时生效的方式,使用环境变量LD_LIBRARY_PATH指定当前路径为动态库搜索路径,命令:
export LD_LIBRARY_PATH=./:$LD_LIBRARY_PATH
这时候再次运行程序就可以正常运行了。
② 演示静态链接
静态库用ar工具来制作。ar是一个归档工具,用于建立、修改、提取归档文件(archive)。一个归档文件可以包含多个目标文件,也被称为静态库。在Linux下,静态库的扩展名一般为.a。
把目标文件hello.o做成静态库,命令:
ar -rv libhello.a hello.o
其中rv参数为组合参数,其中r参数表示当建立的模块名已经存在时,则覆盖同名模块,v参数用来显示附加信息,比如被处理的文件的名字。
使用链接静态库的方法生成可执行程序,命令:
gcc main.o -L. -lhello -o hello_s_lib_test
删除静态库之后,可执行程序也是能正常运行的。事实上,使用链接静态库的方式生成的可执行程序与直接使用目标文件生成的可执行程序没有区别。只是经过了静态库的链接,变为了一个文件,方便于调用、移植和保存。
归档工具ar可以很方便地查看和删除归档文件中的成员。
查看静态库libhello.a中的内容,命令:

关于ar工具更多的命令参数可输入ar –help进行查看。
基本使用如上面静态链接中的用法。
addr2line可以将地址信息转化成函数名或行数。例如,如下代码运行会产生段错误:
test.c:
#include <stdio.h>
int main(void)
{
char *str = "hello";
str[0] = ’a’;
return 0;
}
首先,编译时加上-g参数,产生调试信息。
gcc test.c -g -o test
运行会产生段错误Segmentation fault (core dumped)。此时会产生相关错误系统存于系统日志中。我们可以使用如下命令查看我们当前程序的错误信息:
dmesg | grep test
此时会输出类似如下信息:
[ 1081.831805] test[2763]: segfault at 55f1d81186a4 ip 000055f1d811860d sp 00007ffc6fc1d080 error 7 in test_addr2line[55f1d8118000+1000]
此时借助addr2line工具可以查到产生错误的行号:
addr2line -e test 55f1d81186a4
nm工具用于显示文件中的符号,可以用于各种ELF格式文件。ELF格式文件包括如下三种类型:

nm工具的使用方式:
nm [option] [file]
其中,可以使用nn –help命令来查看支持的参数。其中,nm显示的符号类型如:

其中符号类型有大小写之分,小写字母表示这个符号是局部符号,大写字母表示这个符号是全局符号。
下面一起来使用nm工具查看目标目标文件的标号。
实例代码test.c:
#include <stdio.h>
static int a = 1;
static int b;
void print_hello(void)
{
printf("hello
");
}
int main(void)
{
print_hello();
}
编译之后得到可执行程序test。执行如下命令查看test中的符号:
nm test
输出结果如:
0000000000201010 d a
0000000000201018 b b
# 省略部分内容......
000000000000064d T main
000000000000063a T print_hello
# 省略部分内容......
从输出结果可以知道,a是一个全局符号,该符号位于已初始化数据(RW Data)部分。b也是一个全局符号,该符号位于未初始化数据(BSS)部分。main符号与print_hello符号位于代码部分。
strip工具用于删除文件中的符号。
strip工具的使用方式:
strip [option] [file]
其中,可以使用strip–help命令来查看支持的参数。
我们以nm工具的演示代码来做演示。我们编译得到的可执行程序为test。没有执行strip之前,使用nm命令查看到的符号如:
0000000000201010 d a
0000000000201018 b b
# 省略部分内容......
000000000000064d T main
000000000000063a T print_hello
# 省略部分内容......
使用ls -lh test命令查看test程序的大小为:8.2k。
这时候执行如下命令删除test的符号部分,输出test_strip文件:
strip test -o test_strip
使用nm命令查看test_strip文件是否有符号,显示结果为:
nm: test_strip: no symbols
表示test_strip没有符号。使用ls -lh test_strip命令查看test_strip的大小为:6k。可见去掉符号表之后地程序变小了。在资源有限的系统中,可以使用这种方法为程序进行瘦身。
readelf工具用于显示ELF格式文件的信息。例如:
readelf -h test
输出结果如:
ELF Header:
Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00
Class: ELF64
Data: 2’plement, little endian
Version: 1 (current)
OS/ABI: UNIX - System V
ABI Version: 0
Type: DYN (Shared object file)
Machine: Advanced Micro Devices X86-64
Version: 0x1
Entry point address: 0x530
Start of program headers: 64 (bytes into file)
Start of section headers: 6528 (bytes into file)
Flags: 0x0
Size of this header: 64 (bytes)
Size of program headers: 56 (bytes)
Number of program headers: 9
Size of section headers: 64 (bytes)
Number of section headers: 29
Section header string table index: 28
通过输出信息可以知道文件的类型、文件的格式等信息。
objdump工具用于显示目标文件的信息。
objdump工具的使用方式:
objdump [option] [file]
如:
objdump -h hello.o
输出结果如:
hello.o: file format elf64-x86-64
Sections:
Idx Name Size VMA LMA File off Algn
0 .text 00000013 0000000000000000 0000000000000000 00000040 2**0
CONTENTS, ALLOC, LOAD, RELOC, READONLY, CODE
1 .data 00000000 0000000000000000 0000000000000000 00000053 2**0
CONTENTS, ALLOC, LOAD, DATA
2 .bss 00000000 0000000000000000 0000000000000000 00000053 2**0
ALLOC
3 .rodata 0000000c 0000000000000000 0000000000000000 00000053 2**0
CONTENTS, ALLOC, LOAD, READONLY, DATA
4 .comment 0000002a 0000000000000000 0000000000000000 0000005f 2**0
CONTENTS, READONLY
5 .note.GNU-stack 00000000 0000000000000000 0000000000000000 00000089 2**0
CONTENTS, READONLY
6 .eh_frame 00000038 0000000000000000 0000000000000000 00000090 2**3
CONTENTS, ALLOC, LOAD, RELOC, READONLY, DATA
显示内容包含目标文件各个节的信息。
strings工具用于查看文件中的字符串。
strings工具的使用方式:
strings [option] [file]
其中,可以使用strings–help命令来查看支持的参数。
实例代码test.c:
#include <stdio.h>
int main(void)
{
printf("11111
");
printf("22222
");
printf("33333
");
printf("44444
");
printf("55555
");
}
编译之后得到可执行程序test。执行如下命令查看test中的符号:
strings test
输出结果如:
# 省略部分内容......
11111
22222
33333
44444
55555
# 省略部分内容......
objcopy工具用于对目标文件的内容进行转换。
objcopy工具的使用方式:
objcopy [option] [file]
如使用如下命令可以删除可执行程序test中的.data段输出到test_rm:
objcopy test -R .data test_rm
objcopy配合-R参数的使用可以达到类似strip工具的效果,给程序进行瘦身。
GDB(GNU Debugger)是一个强大的命令行调试工具。在Linux下进行开发,gdb工具是必知必会的工具之一。首先,看一下gdb常用的命令:


下面以实例来进行基本使用的演示:
示例代码gdb_test.c:
#include <stdio.h>
// 测试函数1
void test0(void)
{
int i = -1;
if (i = 0)
printf("i = %d
", i);
else if (i = 1)
printf("i = %d
", i);
else
printf("i = %d
", i);
}
// 测试函数2
void test1(void)
{
int a[10] = {0,1,2,3,4,5,6,7,8,9};
int *p = &a[1];
int *p1 = (int*)(&a + 1);
printf("p[6] = %d
", p[6]);
printf("*(p1 - 1) = %d
", *(p1 - 1));
}
// 主函数
int main(int argc, char *argv[])
{
test0();
test1();
return 0;
}
这个示例代码中有两个测试函数,其实也是两道经典易错的面试笔试题。大家可以先思考一下结果是什么。下面我们使用gdb来一步一步调试及分析。
我们必须编译出带有调试信息(如行号等信息)的可执行文件才能使用gdb进行调试。在以上基础上加个-g参数即可生成调试信息。
除此之外,我们编译时应不使用优化选项,若使用优化,则编译器会对程序进行一些优化,有可能会更改语句的顺序及优化一些变量,从而可能会导致程序执行流程与源码流程不匹配的情况。可以使用-Wall参数打开所有警告,我们的编译命令变为:
gcc -g -Wall gdb_test.c -o gdb_test
使用上面的编译命令编译得到带调试信息的可执行程序gdb_test,有两种方法启动调试。
一种方法是先输入gdb命令进入gdb环境,再输入file+可执行程序装入调试文件,即:

另一种方法是直接输入gdb+可执行程序对该程序进行调试,即:

上面的测试函数1大家思考得出结果了吗?我们单步调试看看结果是怎么样的:



显然,单步运行到了这一句我们就得出了测试函数1的结果,即输出 i = 1。大家分析得对了吗?这要是不注意还真的容易出错,这里的if判断条件里用的是=号,而不是==号,这个小陷阱可能会迷惑一些初学C语言的朋友。
if语句的通用形式为:
if (expression)
statement
可以明确的是:如果对expression为真(非0),则执行statement。本题中,如if (i = 0)其实就等价于
i = 0;
if (i)
显然这里的if语句的expression为假,不会执行statement。
类似的if (i = 1)等价于
i = 1;
if (i)
显然这里的if语句的expression为真,执行statement。
平时在发现自己写的代码执行的流程异常时,不妨debug调试一下,一步一步地走,看程序是否按照自己设计的流程走,看是不是我们的执行逻辑设计错了。
测试函数2也是一道极其经典的面试题目。不能一眼看出结果?没关系,我们一起调试分析一下。接着上面的流程,我们输出quit命令推出gdb环境,再重新进入调试test2。


此时,我们不妨看一下a[1]元素的地址及a数组里面的内容是什么:

可见,在数组初始化之前,整个数组空间里的值是一些随机值。这里反映一个问题,局部变量在初始化之前的值是无规律的,所以不妨在定义局部变量的时候初始化一个确定的值,防止出错。
此时,我们来看一下,指针变量p的值、a数组里的值:

因为此时第20行这条语句还未执行,所以p指向的地址还不是a[1]元素的地址。
再单步往下执行,然后我们看一下,指针变量p的值,及以指针变量p的值为首地址、往后偏移10个内存单元为结束地址,这一段空间内的值是什么:

至此,我们通过调试清晰地得到了p[6]的值。
继续单步往下执行,我们看一下,&a[0]的值、&a的值、(&a+1)的值、p1的值:

从gdb输出的信息我们知道&a的类型是(int (*) [10] ),即是一个指向含有10个元素的整形数组的指针,所以(&a+1)的意义是往后偏移10 * sizeof(int)。进一步,再利用一下其它输出的信息:
&a的值为0x7fffffffdda0
&a+1的值为0x7fffffffddc8
两个值相减得到40,正好是整个数组所占的字节数。
而p1是一个整形指针,所以p1-1指向的就是往前偏移sizeof(int)个字节的地址,即a[9]的地址(0x7fffffffddc4),所以*(p1 – 1)的值也就是a[9]的值。最后我们再看一下&a往后的40个地址里的值都是些什么:

以上就是本次的实例演示,只是用到了一小部分gdb的命令,还有更多命令大家可以自己练习使用,基本的会了,不懂的地方遇到的时候再查也来得及。
可能写得有些乱,但也希望能对大家有帮助。总之,对于一些不确定的知识点或者程序的执行与预期不相符时,不妨调试一下,一步一步看数据有没有异常。
另外,这里使用vscode+gdb命令行来对gdb命令做了基本演示,我们大致知道这么一回事就可以。实际中纯命令行调试的话,着实让人头疼,我们可以vscode+gdb配置一个可视化的调试环境,提高我们的调试效率。
以上就是本次的分享,如果文章对你有帮助,麻烦帮忙三连支持,谢谢!
大家对于文章有什么建议的话也可以留言交流!
巨人的肩膀:
https://baike./item/glibc/10058561?fr=aladdin
https://blog.csdn.net/yasi_xi/article/details/9899599
https://blog.csdn.net/zhengnianli/article
以上就是关于gg游戏修改器新手使用_gg修改器新手教程,用详细过程教你入门,称为游戏高手的全部内容,游戏大佬们学会了吗?

怎么让gg修改器免root使用,免Root使用GG修改器,你需要这个软件! 分类:免root版 7,369人在玩 随着手机游戏的普及,越来越多的玩家开始使用游戏辅助工具,其中最受欢迎的就是GG修改器。然而,很多人不愿意对自己的手机进行Root操作,这也使得他们无法使用GG修改器。幸运的是,……
下载
免root框架下载gg修改器,免root框架下载gg修改器 分类:免root版 6,026人在玩 如果你是一位喜欢玩游戏的人,那么你可能会发现有些游戏需要 root 权限才能使用 gg 修改器这种游戏辅助工具。但是,通过使用免 root 框架下载 gg 修改器,你将不再需要 root 权限就……
下载
gg修改器不需root_GG修改器不需要权 分类:免root版 8,332人在玩 各位游戏大佬大家好,今天小编为大家分享关于gg修改器不需root_GG修改器不需要权的内容,轻松修改游戏数据,赶快来一起来看看吧。 可惜的是 Xposed 官方版本的框架停留在 Android 8……
下载
gg修改器有免root框架吗,下载一个免root框架的gg修改器让游戏变得更加好玩 分类:免root版 5,006人在玩 如果你是一个喜欢玩手机游戏的人,那么你一定知道什么是GG修改器。GG修改器可以帮助你修改游戏数据,例如修改金币、钻石、血量等等。但是大多数的GG修改器需要你的手机root,这对于……
下载
gg修改器无root,下载gg修改器无root让你的游戏更有趣 分类:免root版 7,384人在玩 GG修改器无root是一款非常实用的软件,它可以帮助你修改你的游戏中的一些参数,让你的游戏体验更加丰富多彩。今天我们来为大家介绍这个软件,并分享一些使用心得。 什么是GG修改器……
下载
怎么用gg修改器免root,下载软件:如何使用gg修改器免root 分类:免root版 3,964人在玩 GG修改器是一款非常实用的工具,它可以帮助用户修改游戏中的各种参数,从而获得更好的游戏体验。然而,传统的安装方式需要用户的设备进行root操作,这对于很多用户来说是一个不小的……
下载
gg修改器跳过root,下载gg修改器:越狱神器,轻松跳过root限制 分类:免root版 6,566人在玩 如果你是一名Android手机用户,那么你一定会遇到一个非常棘手的问题:无法使用某些应用程序或者玩某些游戏,因为它们需要在已经进行了root权限的设备上运行。然而,对于很多人来说……
下载
gg修改器root启动失败,GG修改器root启动失败?别担心,这款软件能解决你的问题 分类:免root版 6,448人在玩 如果你是一位游戏玩家,那么一定会经常遇到一些游戏中的难点或者关卡。而此时使用GG修改器,可以帮助你轻松地解决这些问题,并让你更好地享受游戏乐趣。但是有时候,当你想要使用GG……
下载
gg软件修改器免root版,下载GG软件修改器免root版,轻松修改游戏体验 分类:免root版 6,384人在玩 GG软件修改器是一款非常有用的工具,它可以帮助玩家修改游戏数据,让你在游戏中轻松获得更好的体验。而且,与其他类似工具相比,GG软件修改器免root版使用起来也非常简单方便。 无……
下载
gg修改器root网址,软件推荐:GG修改器root版 分类:免root版 6,345人在玩 如果您是一名游戏爱好者,想要更加畅快地享受游戏乐趣,那么今天向大家推荐一款非常不错的软件——GG修改器root版。这款软件可以帮助您在游戏中修改各种参数,让您能够轻松获得游戏中……
下载